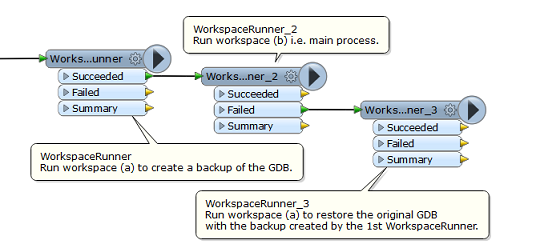
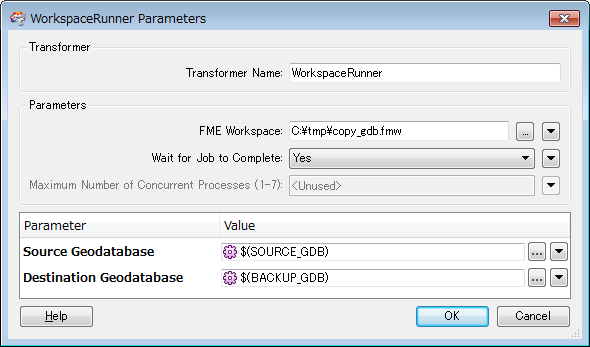
I need to load data from multiple reader to a single writer . I would like to take a backup of the current data before the process begins . I would like to set the option to truncate the features in the output GDB and reload from all the readers . During this process if it fails is there any way to roll back the process ?
Can anyone help please . Thanks