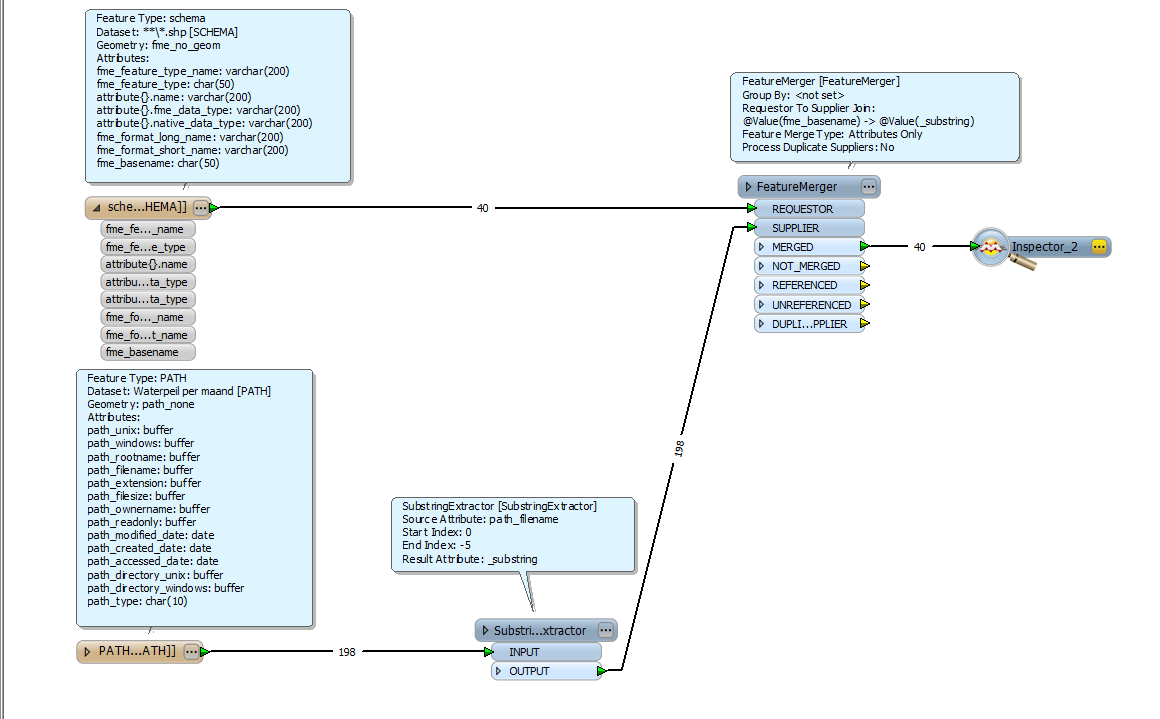
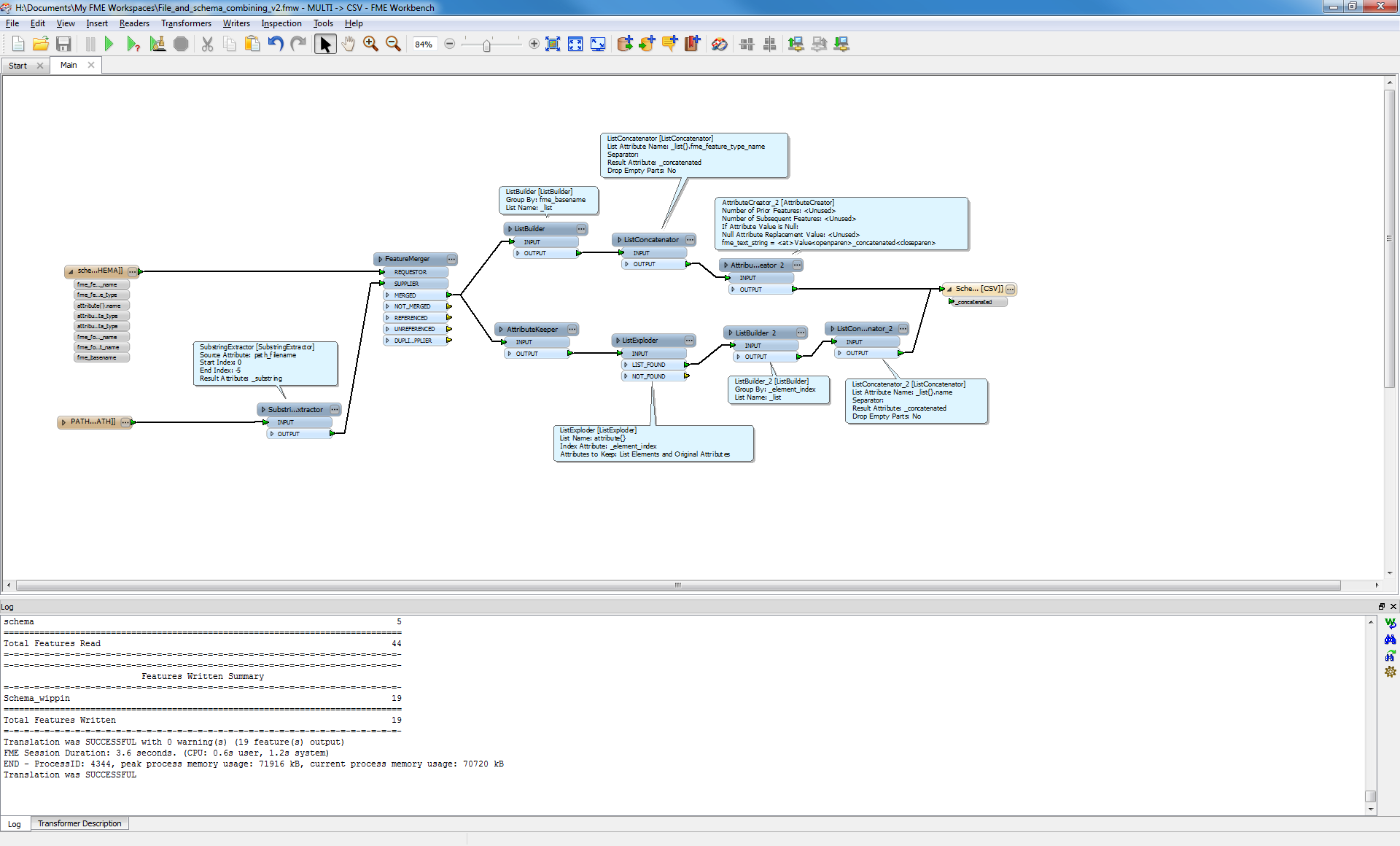
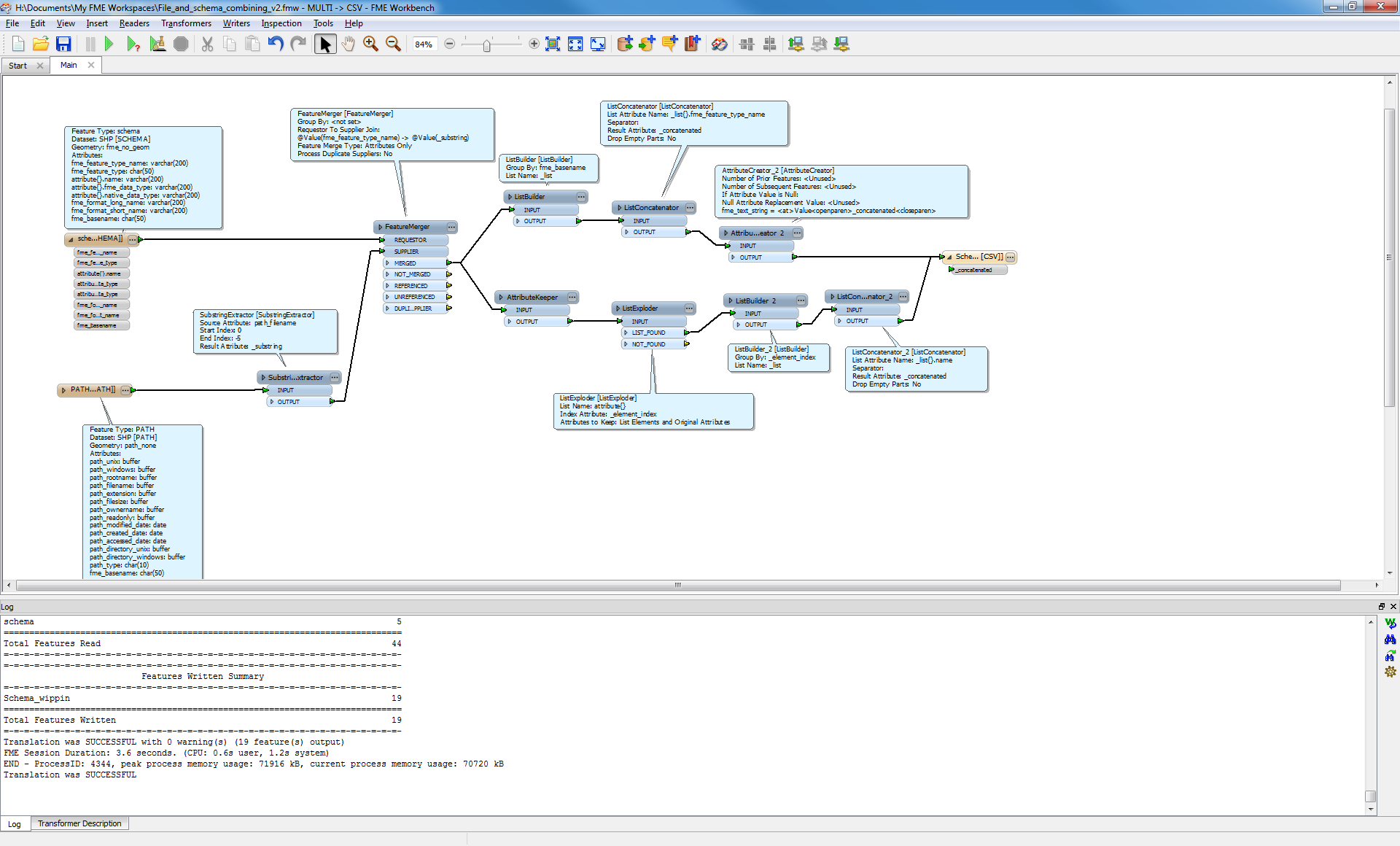
I'm finding it quite difficult to figure out how to dynamically produce attributes per my "fme_basename". So let me explain what I have, and what I want.
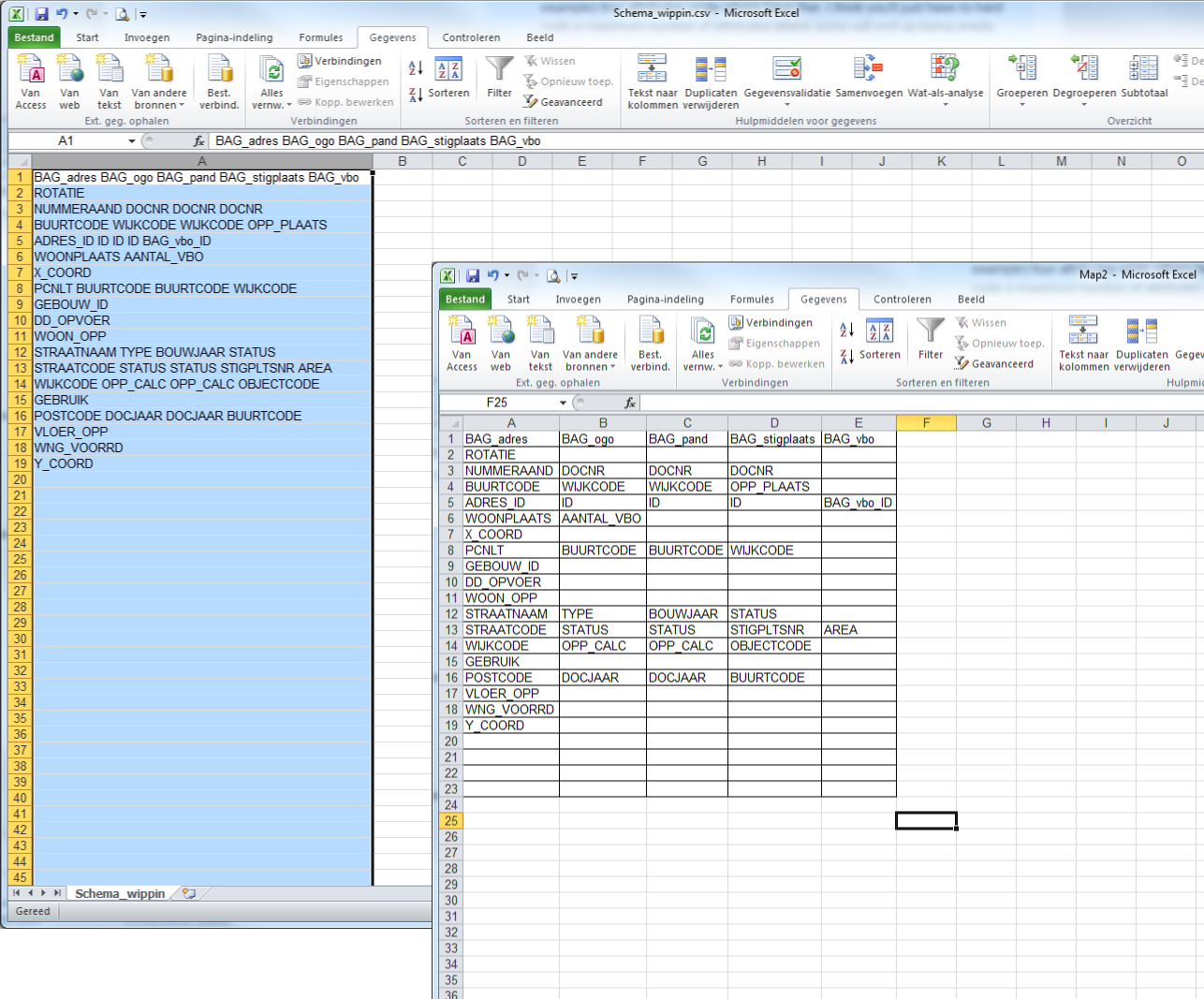
My source is a folder with multiple undetermined shape files in. My output is a .xls file that simply lists the attributes present for each shapefile within my source. So in other words, my writer fans out by "fme_basename". Everything works fine, but instead of each shapefile being represented by a new tab, I'd like for them all to be on one page, in other words, an attribute created for each shapefile found. The intent of the entire workspace is just to summarise all shapefiles for the user, so that they can ensure all fields that should be present are, for each shape file.
So what I have is:
"ATTRIBUTES" (The field I created that lists all present fields)
Type
Name
level
etc
[Roadnetwork] (This is the tab in the xls)
This is present for each tab generated, where each tab is named accodring to the shape file, such as Roadnetwork.shp, Landuse.shp, or WaterArea.shp
What I want:
Roadnetwork Landuse WaterArea
Type Type Type
Name Code Name
level Hight Depth
etc...
[Workspace]
So in short, I wont what is now represented by tabs to become attributes instead. However, keep in mind, the source will always be a folder, and the shape files inside can be anything. Do it need to be purely dynamic.
Thanks in advance, especially for enduring my crude graphical representation above :)