


Hello,
I wonder if anyone has experience in both FME and Pentaho. I have several years experience in FME, but know nothing about Pentaho.
Currently our team of Pentaho users considers the switch to FME. I have shown the possibilities and when it comes to functionality, FME seems very promising! However, Pentaho seems to be 6 times faster than FME... This might be a showstopper and we want to know whats is causing this. Does anyone have experience to get better performance writing to (or reading from) Oracle datasets? I never had the experience that FME is slow in reading/writing to Oracle, but when I see the speed of Pentaho, I was surprised of its speed.
We did a test of a ETL-script that reads about 912.000 records from an Oracle Database and writes the result directly to another Oracle table. In short: SQLCreator (type Oracle) --> FeatureWriter (type Oracle). Duration in FME: 5 - 6 minutes; duration in Pentaho is about 45 seconds. We were reading and writing to the very same databases, using the very same SQL-statement. Pentaho en FME were both running on comparable hardware (VM's), same OS, same CPU's, same amount of RAM, disk space (and speed), same network, etc.
After this first test I have done several tests reading from and writing to different FileFormats (JDBC (Oracle), ESRI FileGeoDatabase, FFS) and checking various types of settings in FME Desktop. It didn't surprise me that the fastest process was the FFS --> FFS translation, timed at 2 minutes 0 seconds. The translation from Oracle Non Spatial to Oracle Non Spatial took 5 minutes 16 seconds run on FME Desktop, and about 4 minutes and 9 seconds on FME Server. Performance via JDBC dropped to 13 - 14 minutes.
Is FME simply 'slow' compared to Pentaho - which I cannot imagine - or am I sim[ply missing some important 'tuning' settings for Oracle. Can anybody help me?
Thanks in advance,
Frank van Doorne









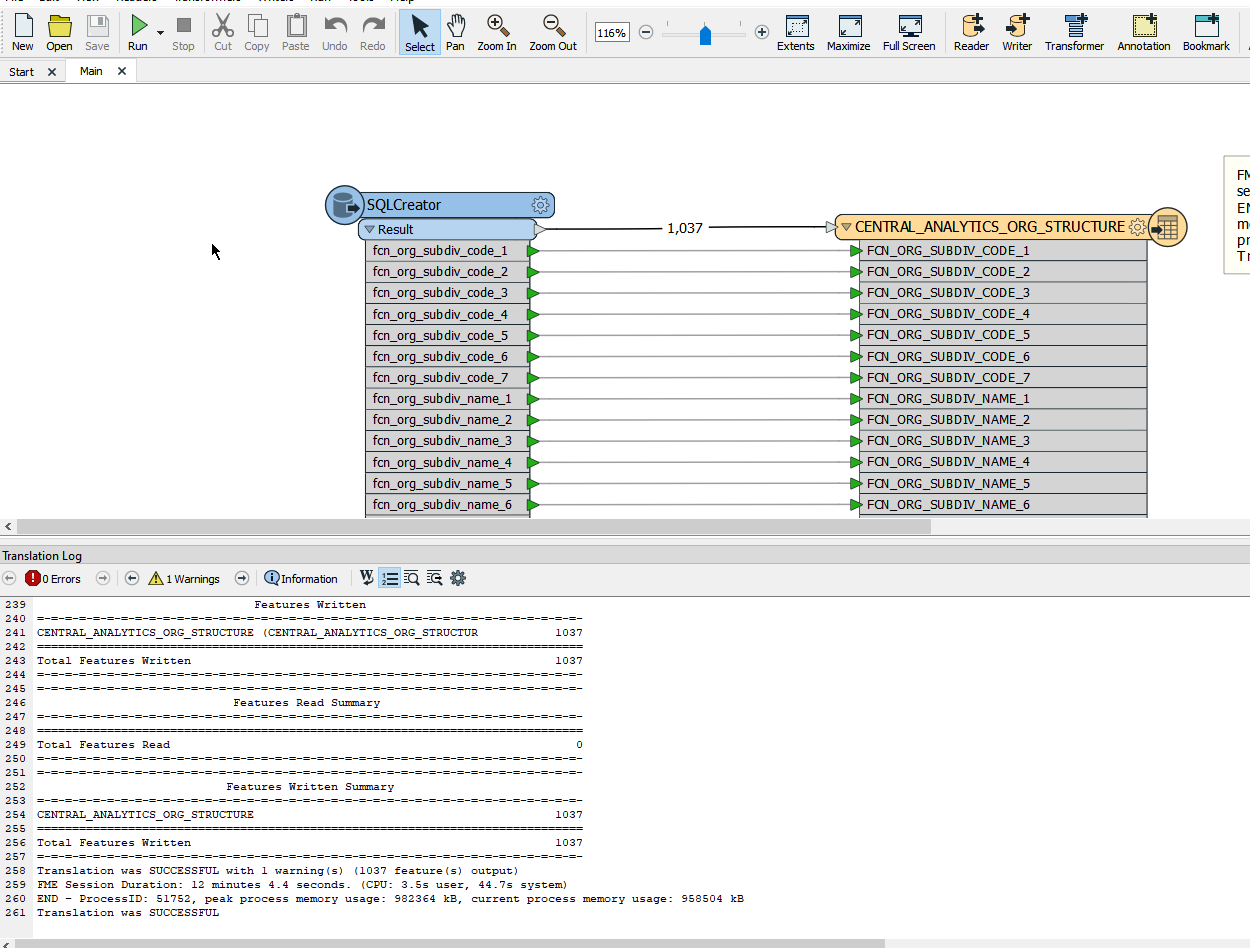
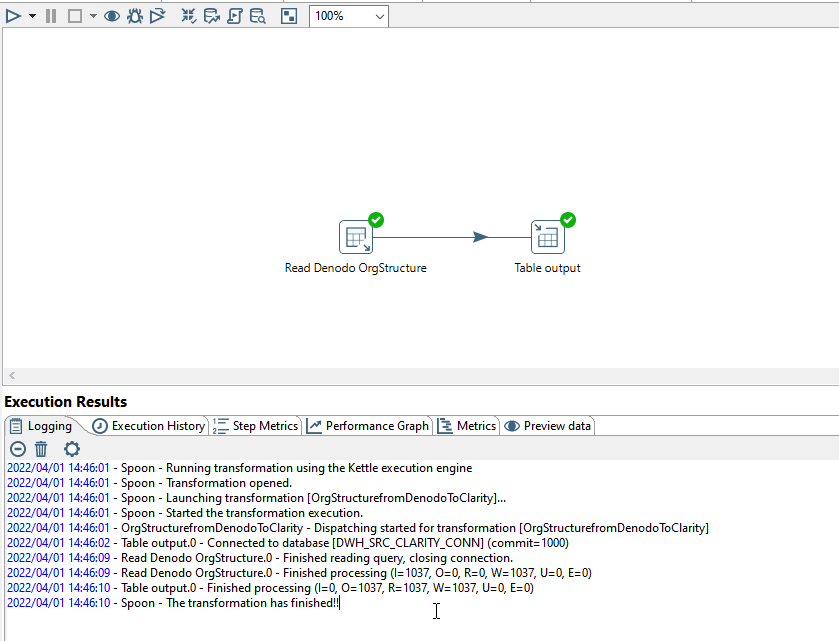 Now I am not sure if I am missing something basic with the FME workbench, but I did try to play with bulk write size and features per transaction without any success. And my data has nothing to do with spatial, it is plain old int, date, and string data.
Now I am not sure if I am missing something basic with the FME workbench, but I did try to play with bulk write size and features per transaction without any success. And my data has nothing to do with spatial, it is plain old int, date, and string data.