")

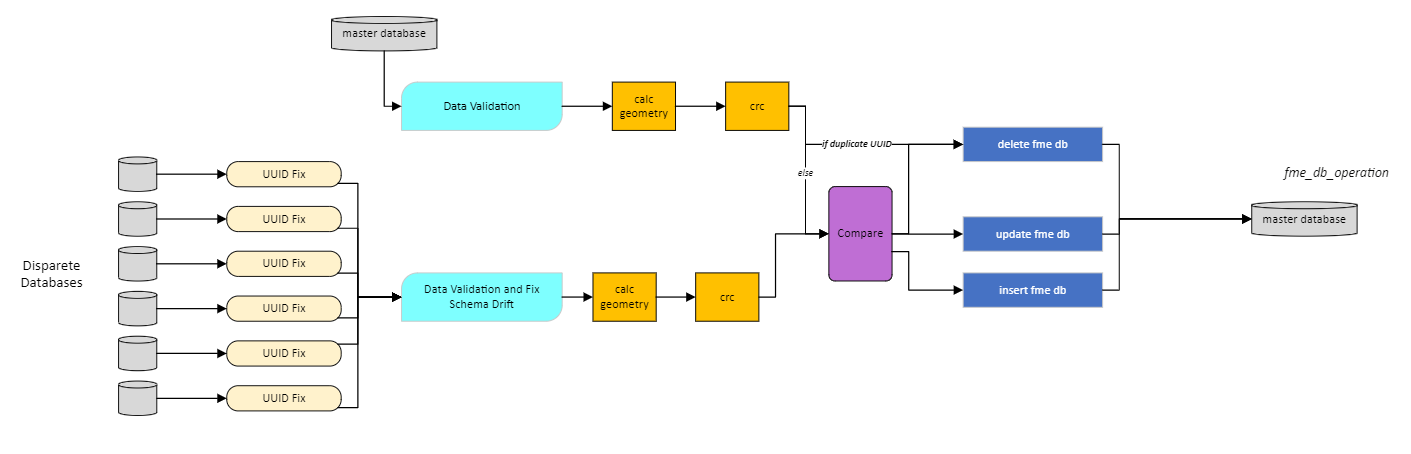
Would like to hear the opinions of the collective on best practices for writing features back to a SQL database. Specifically Intergraph SQL in my case, but I guess this could apply to many formats.
I have a table with millions of linear features that need to go through a LineCombiner process before being written back to the same database. The big question….what is the best methodology for deleting the old geometry and inserting the new? Two methods I’ve used in the past, each with their own downsides.
• SQLExecutor/DatabaseDeleter based on the unique ID. Main concern with this is if the translation fails after the Delete but before the writing of new features, those features are gone.
• Let the writer do a DELETE/INSERT (fme_db_operation). To me this is safer, but can take twice as long due to number of transactions.
I can’t simply truncate the table because we are sometimes only reading a subset of the features in a specific AOI within the database. Truncating would also delete the features outside of our AOI.
Is there another method I’m missing?