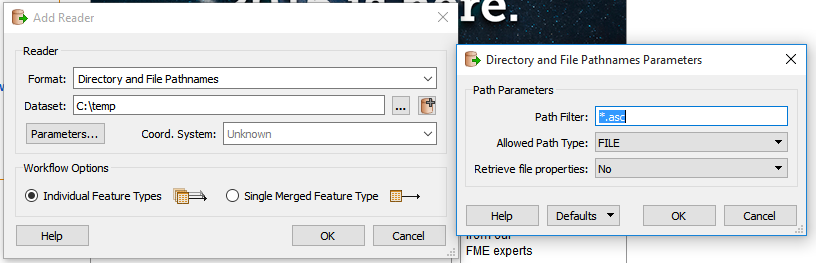
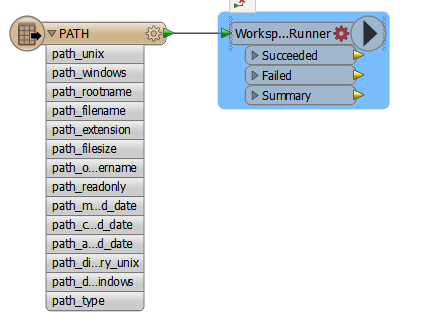
So i have a workspace that
- imports all ascii grid files in a directory
- does a raster to point conversion (RasterCellCoercer)
- offsets points by half cell size - so point at cell center rather than lower left corner (OffSetter)
- adds XYZ attributes (AttributeCreator)
- Finally writes to MapInfo Tab files
by default FME seems to import all my ascii files and hold everything in memory before committing the outputs. so my model is a RAM hog.
How can i adapt the model so each ascii tile goes through the process one after another which should need significantly less RAM.