hello,
Currently i try to do a batch deploy an apply the same workbench on 89 file. When I use the "batch deploy", all the files are process but the files are saved under the same name which means that they are deleted as they go along, in the end I only have 1 file left instead of the 89 starting...
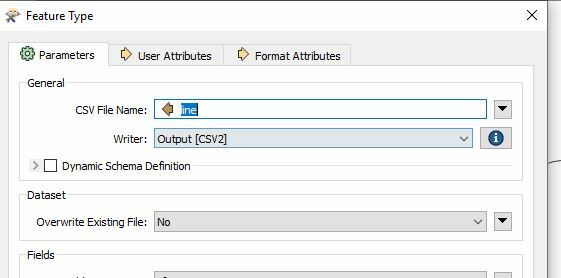
The output file names are defined in relation to a number extracted from the input file name and stored in an attribute. I think that's where my concern comes from, but I don't know how to solve it.
Example :
Input files is name "trajectory0001.txt" and it have this constitution :

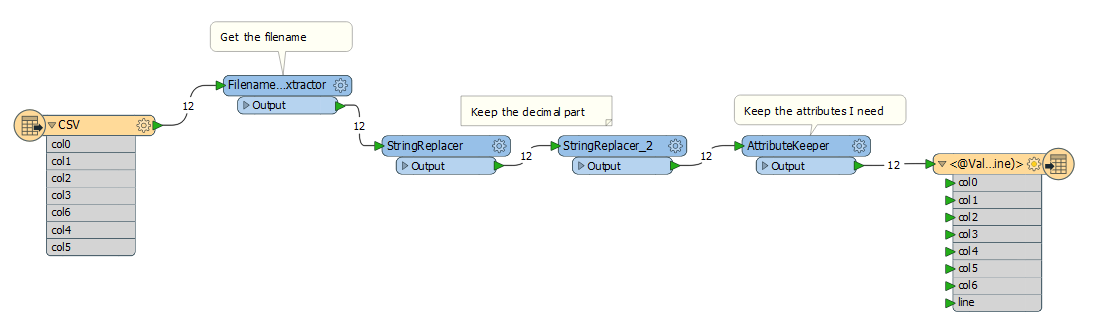
In the FME I extract the filename and I keep the decimal part and I put it in new attribut (call "line").
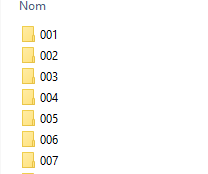
So I have these file in output.

The output file is name 001.csv because I based the file name on the value of "line" attribut.
My reader is may be wrongly defined so that it always takes the same file name but I'm not sure.
I don't know how to solve my problem ...
Arnaud