

I have a large polygon dataset on which I want to run an AreaOnAreaOverlayer. The transformer take a very long time to run because there are ~100,000 polygons and I don't have any way to group the polygons.
It's occurred to me that I could enable parallel processing if I could group the polygons into subgroups that actually overlap each other. I can do this manually by lassoing the polygon groups by eye in ArcGIS and adding a unique value to a new field for each subgroup but I wondered if there was a clever way to automate this in FME?
Below is the layer of polygons on which I want to run an AreaOnAreaOverlayer (I'm hoping to create a layer with no overlaps of all of the polygons intersected and attributed with a count of how many overlaps there are in each polygon)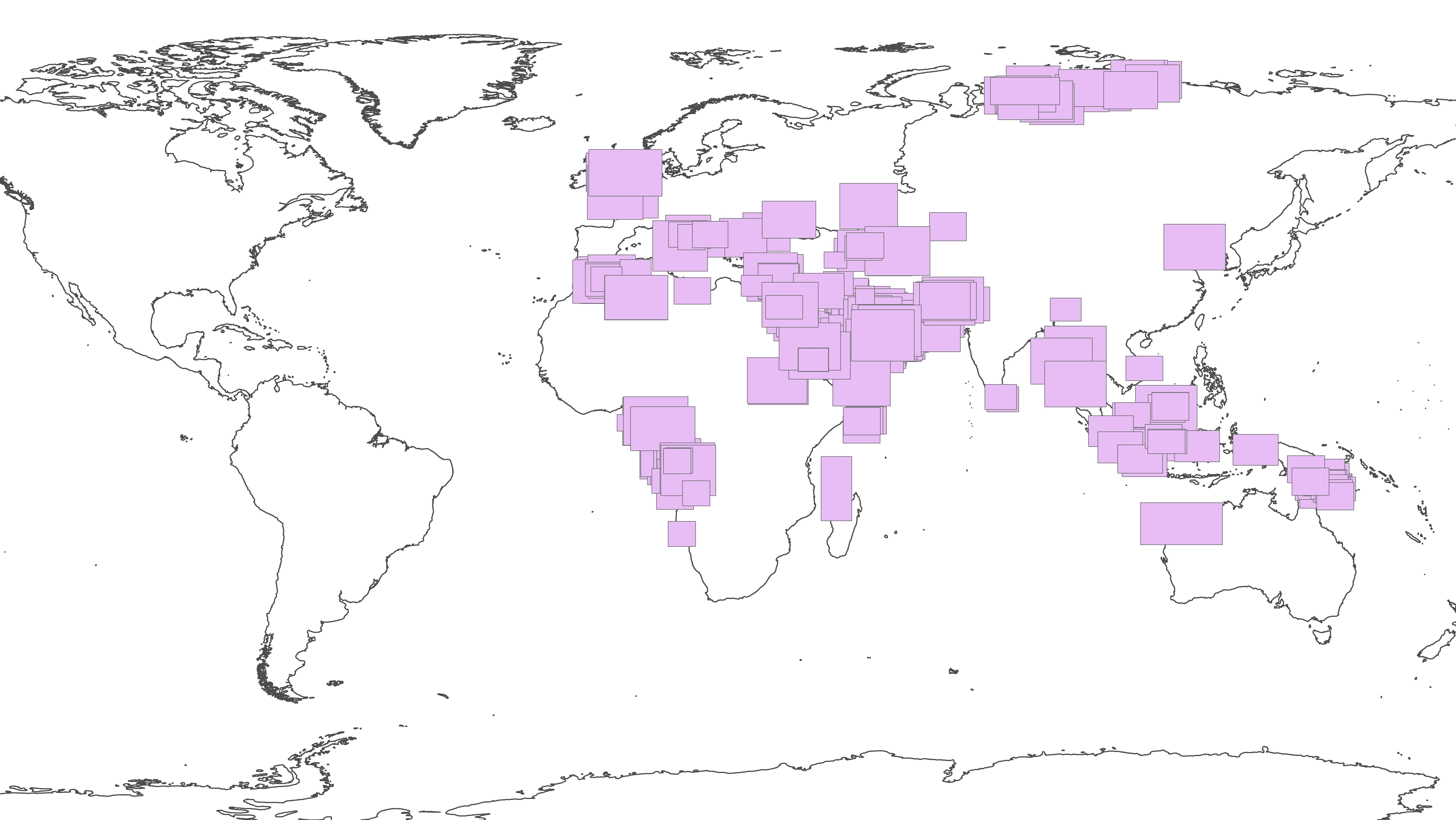
I imagine it will run faster if I can group them into layers that don't overlap at all, and then use that field in the "Group By" parameter.
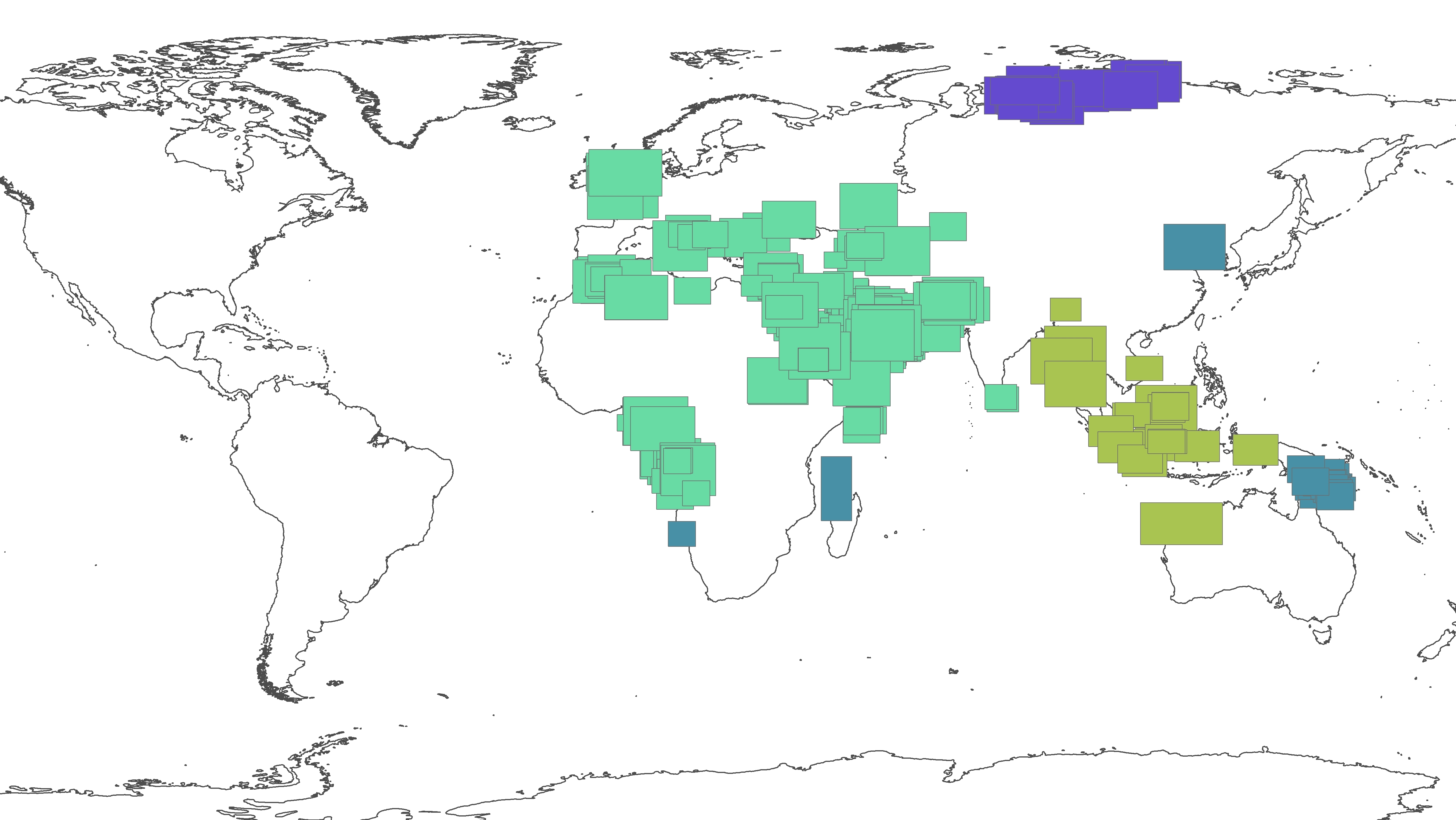
I'd be really grateful for any advice about any stage of the workflow. At the moment, the workspace is running prohibitively slowly. Thanks a lot in advance!




