

")

Hello!
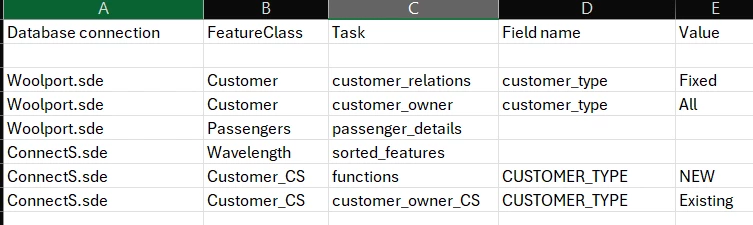
I’m working on building a scalable FME workspace that can update multiple databases using a configuration CSV file. The CSV includes: Database connections, Table names, Field names (used to map different attribute names across databases)
Since each database may use different field names for the same data, I added a “Field Name” column to the CSV to facilitate attribute mapping.
What I am trying to do is loop through each row in the CSV, and for each row: Read the database connection and table name, Use the field names from the CSV to map attributes dynamically, Join the data with another source using a Feature Merger. Perform updates based on the joined data.
To do this, I’ve:
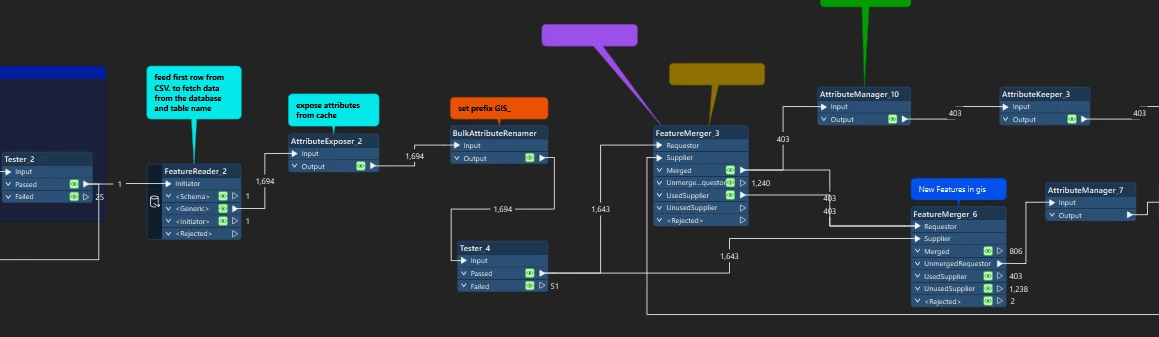
- Read the CSV into a list.
- Set up a counter and a list element extractor to go through one row at a time.
- Used a Tester to check each row and feed the correct connection and table name into a FeatureReader.
- After the FeatureReader, I merge it with another dataset and apply logic to update the database.
The Roadblocks
- FeatureReader Port is Generic:
When reading from a table, the FeatureReader outputs features through a generic port. The exposed attributes don’t update dynamically when the next row is processed (i.e., when reading a new table with a different schema). - Field Name Mapping in AttributeManager:
I can’t dynamically map field names in the AttributeManager because I can’t easily use the field names from the CSV as variable references to rename or map attributes.
My goal is to have the workspace handle all databases dynamically without needing to rebuild it every time a new database or table is added. I should only need to update the CSV to scale the process.
Any help in overcoming these roadblocks would be greatly appreciated!
Here is what my current workspace looks like:

CSV:
Thanks!

