Happy 2025!
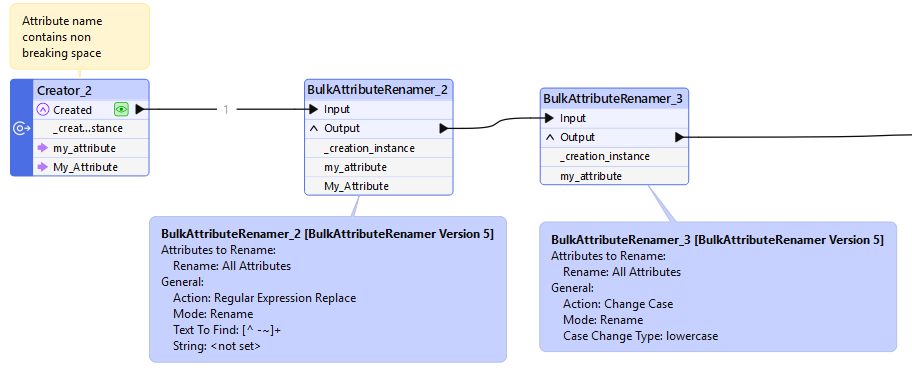
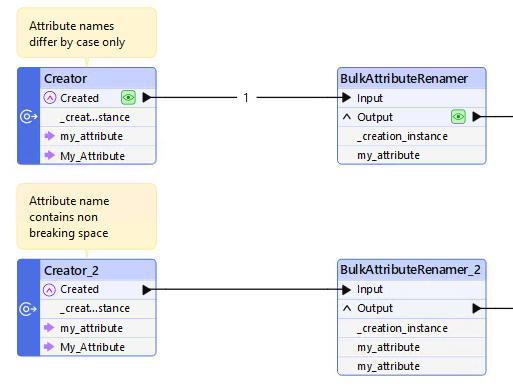
I’m processing some OpenStreetMap PBF data and have found a duplicate attribute name, hard to believe but I think an artifact of OSM’s XML ancestry, two attributes differ only in string case, like my_attribute and My_Attibute. My processing changes all attributes to lowercase so I have two fields my_attribute. I tried a ListDuplicateRemover on the Schema output of a SchemaScanner but I get an invalid schema definition. Does anyone with knowledge of FME internals have a tip for dropping one of the duplicate attributes? Thanks.