



Hey Team,
We’re getting a really weird error on Flow/Server (2022.2), and unfortunately it seems to be one of those ones that we can’t really replicate!
The Infrastructure setup is two hosts, with a mixture of standard engines and dynamic engines.
We got the below errors across two (very) different workbenches, on the same engine/host (standard engine):

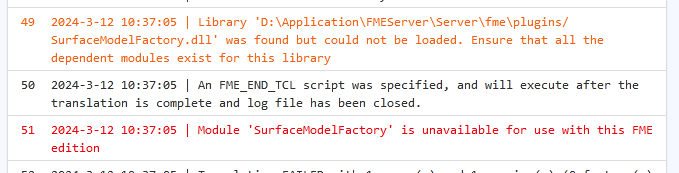
We had something similar a couple of weeks ago and resolved it by restarting the effected host. However, this time around it has seemed to fix itself (assuming it was restarted as part of the automatic engine recycling).
Looking at the engine logs for that host, they don’t really give too much more info as to what has happened
Tue-12-Mar-2024 10:37:00.923 AM INFORM Thread-13401 BANPRIFMESP01_Engine2 Translation Finished (service '7070'). Return message is '23001:Module 'SurfaceModelFactory' is unavailable for use with this FME edition|LogFileName=job_522412.log'
Wondering if anyone has seen something similar or know what might be causing this?



