


I'm having some weird behaviour with my FME server in the Cloud that I could not explain.
We are using a server that has three active engines and the following Queue-system:
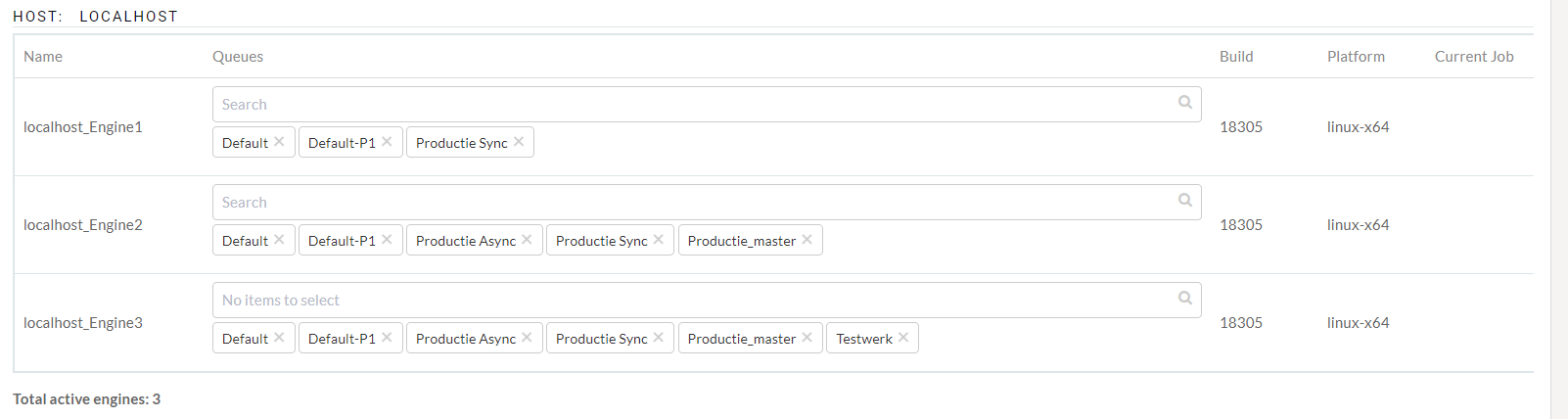
This morning we had a workflow in our production sync queue that took way to many resources and time to process and was aborted. Somehow the server had some problems after (or during/before?) this because all new jobs where not properly handled and all got queued in line. Only engine 2 took was able to start new jobs even tho the other two engines where free and not running. With a unstable and high load as result (20000ms response time and server load of 100) and two engines IDLE. To compare it: Normally our response time is 5ms with an average load of between 0.10 and 0.50.
A reboot was needed for the server to stop the load en activate the other 2 engines.
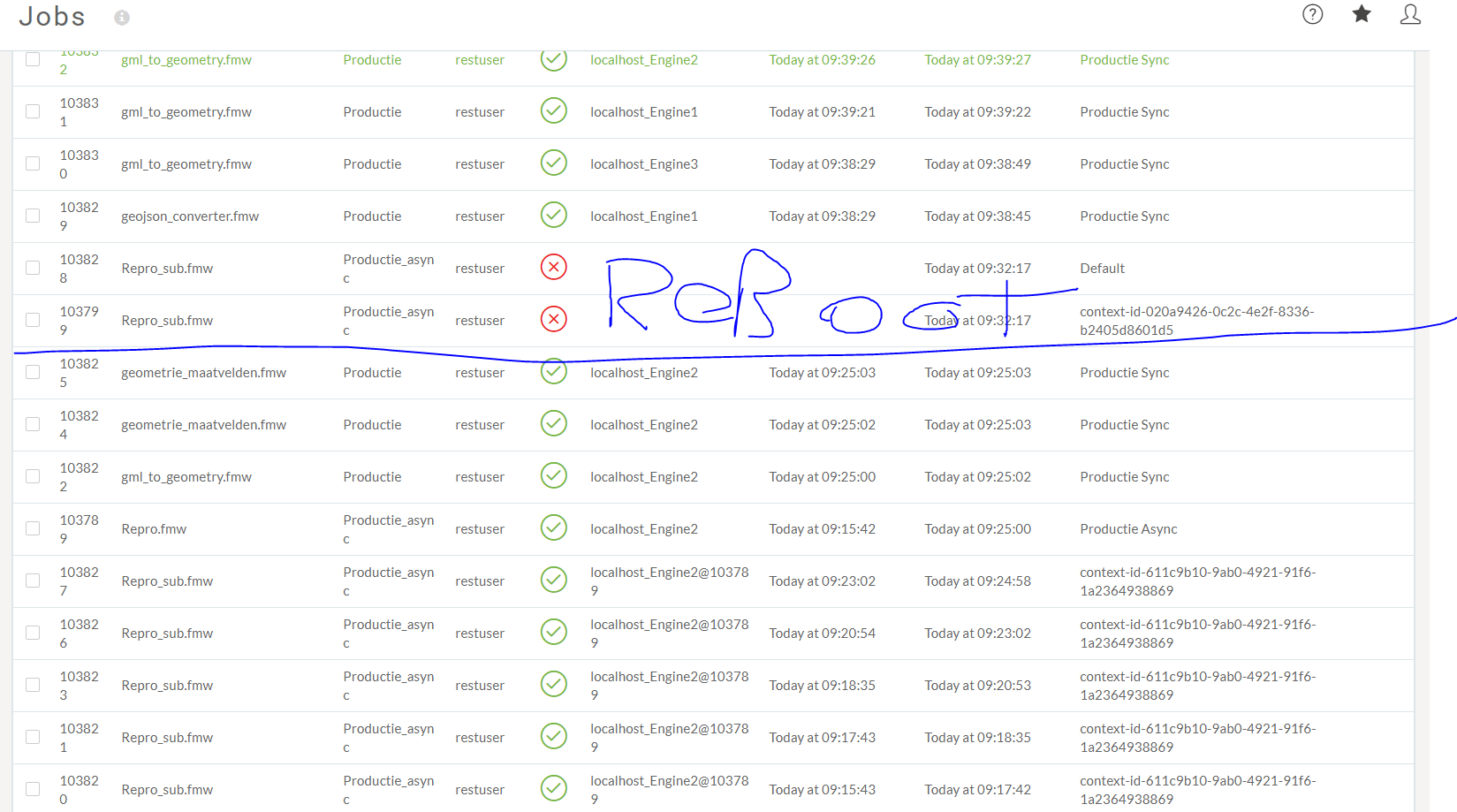
Is there any way to prevent this form happening again or a place where i can dig deeper into what could have caused this?





