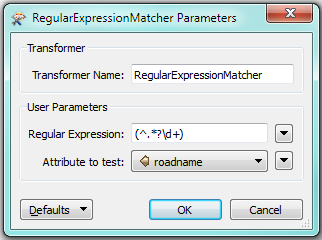
I am cleaning up a huge adress dataset and I am now stuck so I hope someone here has an idea.
I have a large amount of adresses in one attribute column that are all composed of the following:
"road name" "road number" "junk i need to remove"
example:
fictive street 123 ,23-65
My problem is that I want to remove everything after the road number (ie: ,23-65)
the road names can contain x numbers of characters with a random number of white spaces. I'm guessing I need to use regular expressions but I can't figure out how to select and remove all the junk text. the junk always comes after the road number and a white space, tje junk can be a random number of characters long.
Any ideas?