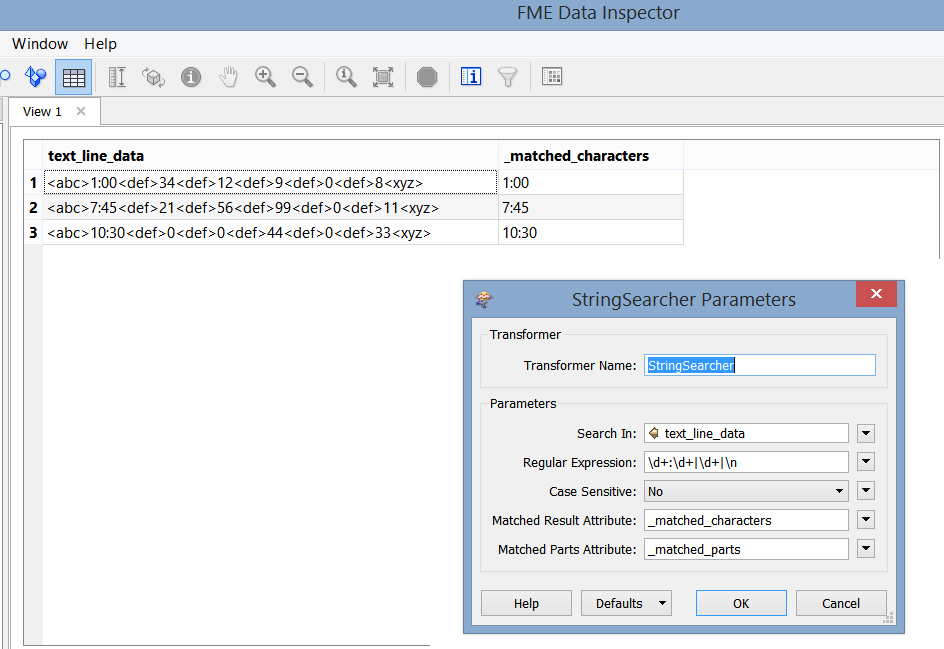
From the following sample text string........
<abc>1:00<def>34<def>12<def>9<def>0<def>8<xyz>
<abc>7:45<def>21<def>56<def>99<def>0<def>11<xyz>
<abc>10:30<def>0<def>0<def>44<def>0<def>33<xyz>
......I'm trying to extract times and data ie end up with the times (eg 7:45) and the numeric data eg 21 56 etc
.............
As a test bed I sometimes use Rubular or RegExr for testing regular expressions - both pretty good,
The following expression does exactly what I want:
\\d+:\\d+|\\d+|\\n
Both test beds - Rubular and RegExr return the required data and do exactly what I want.
..........
However putting this expression in the FME StringSearcher Transformer only returns the first Group ie 1:00 then 7:45 etc
.......
My question is - why is there a difference between what RegEx in FME returns and what Rubular and RegExr returns ???
........
See attached screen dumps.
Any help much appreciated.
.........
PS
The above expression also works fine in RegexBuddy (same as Rubular)
.........
Cheers
Howard L'