



I am reading in a very poorly formatted JSON file which has hundreds of lines but I just want to extract some key attributes that will then be used to create a JSON file that can be passed to FME Flow to start a work bench using the extracted attributes.
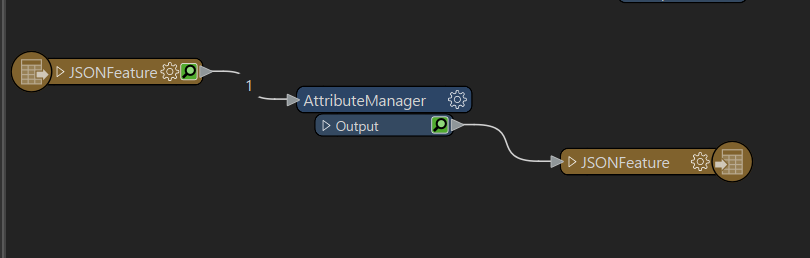
I am reading the JSON file in and running it through an attribute manager to get the attributes I need. If I then run through JSON writer I just get a list like this
[
{
"json_featuretype" : "JSONFeature",
"Catalogue Key" : "Data Catalogue",
"Layer Name" : "Testville Roads",
"Data From" : "Import type from CSV file",
"Data Access" : "Restricted",
"Update User" : "Alex",
"Description" : "Roads data for Testville COuncil",
"Dataset Dimension" : "3D",
"Data Update Frequency" : "As needed",
"Geometry Type" : "Points",
"Spatial Presentation Type" : "Vector",
"Data Currency" : "2025-11-09",
"Initial Publication Date" : "2025-04-15",
"Contact" : "Fred Flintstone",
"Data Classification" : "Business Impact Levels (BIL)",
"Dataset Aggregator" : "Spatial Test",
"Organisation" : "Spatial Test",
"Data Distributor" : "Spatial Test",
"Data Transfer Medium" : "File Upload",
"Creation Request Key" : "DNSS-60064"
}
]
But what I want is to end up with a file like the following:
{
"publishedParameters": [
{
"name": "Layer Name",
"value": "Testville Roads"
},
{
"name": "Data Access",
"value": "Restricted"
}
]
}
What is the best approach to pass these parameters to FME Flow so they can be used to populate the parameter files in the Flow workbench?

