


Hi folks,
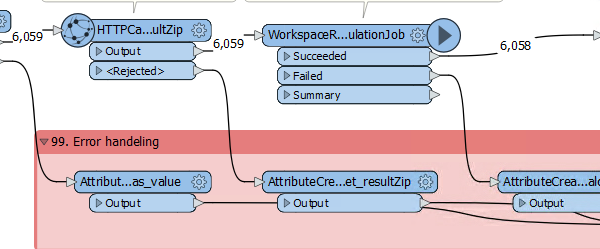
I developed an FME workspace that connects to an api service. The workspace is quite elaborate, but in its basics its sends (calculation) jobs to an api, periodically requests a status update from the api to see which jobs completed, and downloads the results for all jobs that are completed.
If I look at the FME workspace I see that in total 5469 (calculation jobs) were initialized, and it seems that the monitoring process has identified 590 jobs to complete. If I however manually request a new status from the api, it seems that (nearly) all jobs in fact completed, but many did so after the latest time instant that was logged during the translation (2020-09-18 17:41:26). Also if I look in my resultFiles folder for the jobs that were downloaded, I see that the latest resultFile was downloaded at 18-09-2020 17:41...
I notice that the workspace indicates to be still running, but there doesn't seem to be any progress anymore. If I look at the translation log within workbench, I see that the translation log has exactly reached 1000000 lines, and the translation seems to have stalled from there. However, the first line that is shown in the translation log within workbench
(which is '2020-09-18 05:13:28|32496.7| 0.0|STATS |aeConnectCalculate_2::aeConnectCalculate_mainCalculations_Logger_Information LOGGED Transformer Output Nuker (TeeFactory): Cloned 0 input feature(s) into 0 output feature(s)'),
is actually not the first line of the physical log file
(latter is '2020-09-17 15:23:57| 0.6| 0.6|INFORM|FME 2020.0.2.1 (20200511 - Build 20238 - WIN64)'),
so it seems that FME only shows the last 1 million lines in the translation log window of workbench.
Just curious, is this true, and is this configurable in some way?
If I look at the physical logfile, it seems that is has grown into quite a sizeable file of 532944 kb, with a total of 2687610 lines written, where the last line is the same one as the one shown in the translation log window of fme workbench. Given the size it's quite close to half of a gb. Could it be true that FME holds a limitation for the size that the physical log file can hold?
I now also realize that it might be wise for me to turn off informational log elements to be written to the logfile (i.e. uncheck 'Log Information' under 'Log Message Filter' of the 'Translation' tab of the 'FME Options'). In this way the issue I ran into might be prevented.
For now I'm mainly curious to know if it could be possible that the logging methodology of FME has anything to do with the stalling of the workspace that I experienced.
I already checked for some settings that might be related to the logging in FME, but I can't seem to find one that points to a setting/restriction of 1000000 lines in the translation log window of FME workbench, or a setting/restriction to the size of the physical log file of FME translation can hold.
What I found was;
--> This to me seems like a setting that is targetted at logger transformers in the workspace (and/or maybe automatic error/warning logging of FME). I see that for me I didn't change these settings, and in the workspace parameter defaults it is configured to Max Features To Log = 200 and Max features to record = 200
Furthermore I thought and saw some items pointing towards 32 vs 64 bits versions and available RAM, but I don't think that is the issue here. The translation doesn't require that much ram, especially not for the monitoring part. Also, I have feature caching disabled. Some lines on the log that might be interesting on this front;
2020-09-17 15:23:57| 0.6| 0.6|INFORM|FME 2020.0.2.1 (20200511 - Build 20238 - WIN64)
2020-09-17 15:23:57| 0.6| 0.0|INFORM|FME Desktop Professional Edition (floating)
2020-09-17 15:23:57| 0.6| 0.0|INFORM|START - ProcessID: 6756, peak process memory usage: 39200 kB, current process memory usage: 39200 kB
2020-09-17 15:23:58| 1.0| 0.0|INFORM|FME Configuration: FME_PRODUCT_NAME is 'FME(R) 2020.0.2.1'
2020-09-17 15:23:58| 1.0| 0.0|INFORM|System Status: 336.57 GB of disk space available in the FME temporary folder (D:\\TempAppData)
2020-09-17 15:23:58| 1.0| 0.0|INFORM|System Status: 64.00 GB of physical memory available
2020-09-17 15:23:58| 1.0| 0.0|INFORM|System Status: 68.00 GB of virtual memory available
2020-09-17 15:23:58| 1.0| 0.0|INFORM|Operating System: Microsoft Windows Server 2012 R2 Server 4.0 64-bit (Build 9600)
2020-09-17 15:23:58| 1.0| 0.0|INFORM|FME Platform: WIN64
2020-09-17 15:23:58| 1.0| 0.0|INFORM|Locale: nl_NL
2020-09-17 15:23:58| 1.0| 0.0|INFORM|System Encoding: windows-1252
2020-09-17 15:23:58| 1.0| 0.0|INFORM|FME Configuration: Start freeing memory when the process exceeds 192.00 GB
2020-09-17 15:23:58| 1.0| 0.0|INFORM|FME Configuration: Stop freeing memory when the process is below 144.00 GB
Ideas or suggestions on whether the logging methodology of FME might be linked to the stalling of my workspace are greatly appreciated.
Kind regards,
Thijs



 Hi
Hi