Hi there,
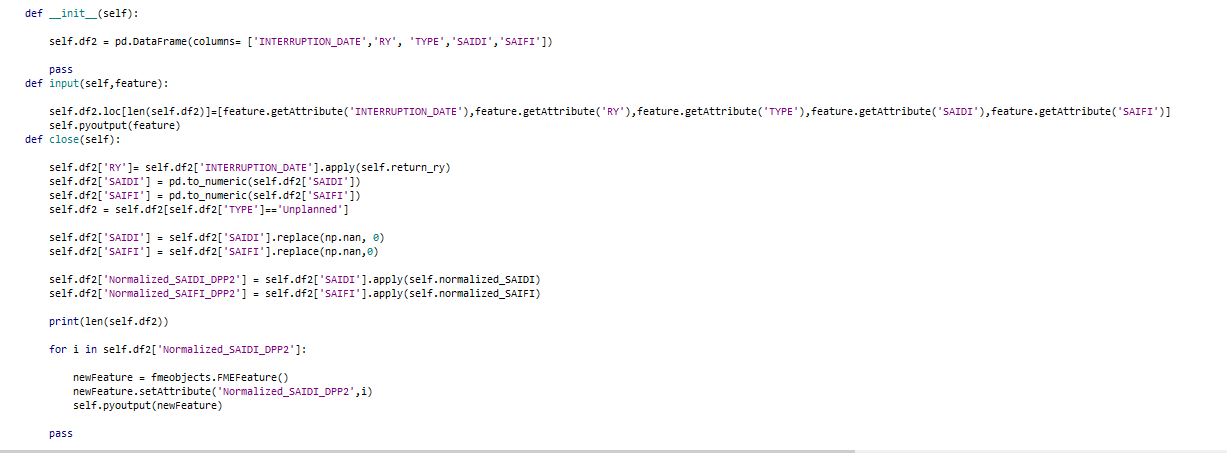
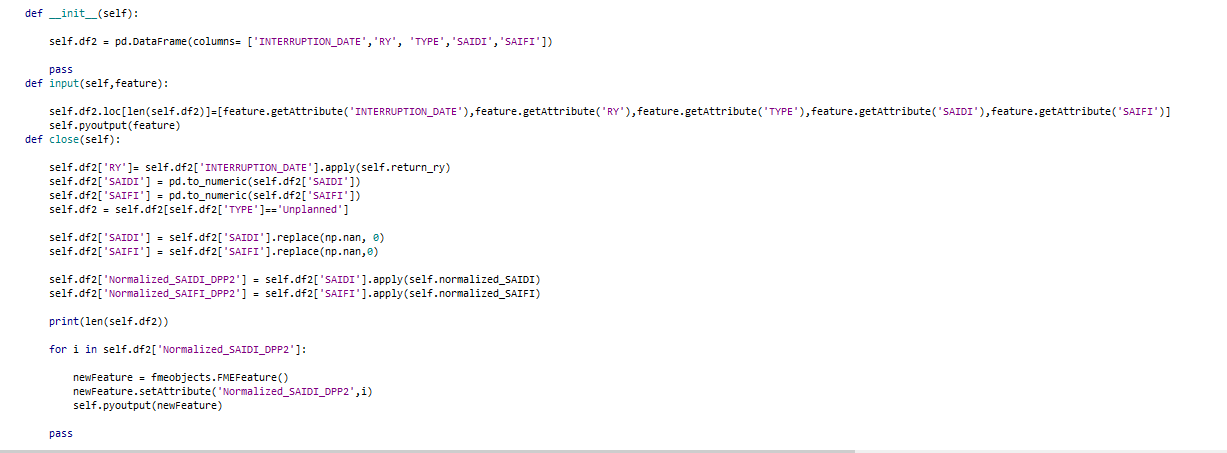
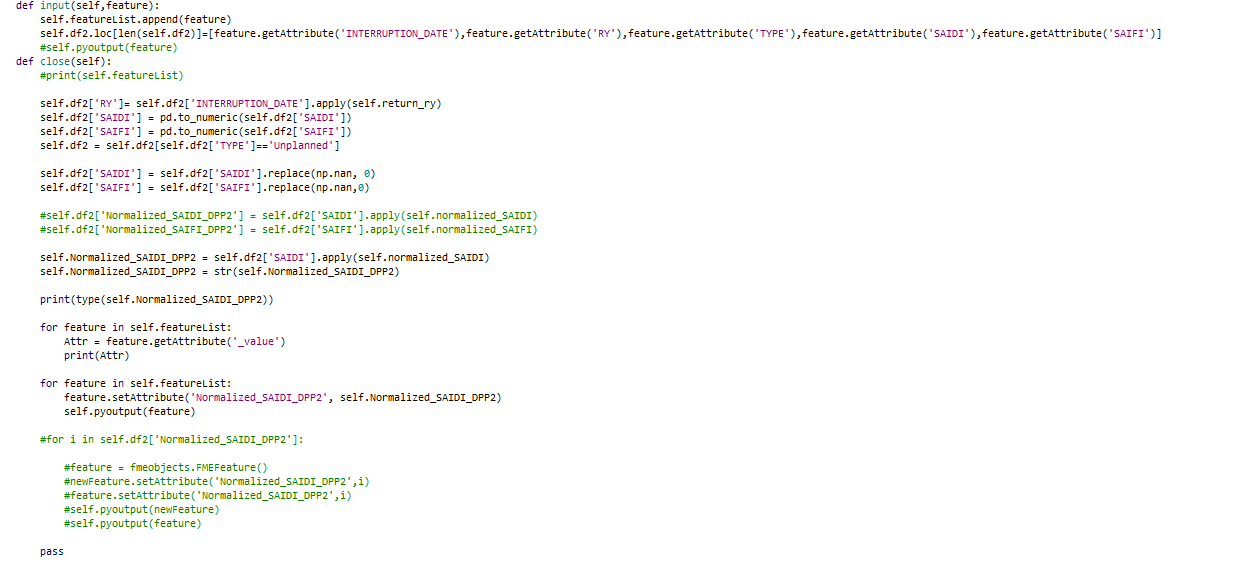
I have calculated an attribute by using the Python script in Python caller. I tried to add the attribute in the output using following code at the close function:
for i in self.df2['Normalized_SAIDI_DPP2']:
newFeature = fmeobjects.FMEFeature()
newFeature.setAttribute('Normalized_SAIDI_DPP2',i)
self.pyoutput(newFeature)
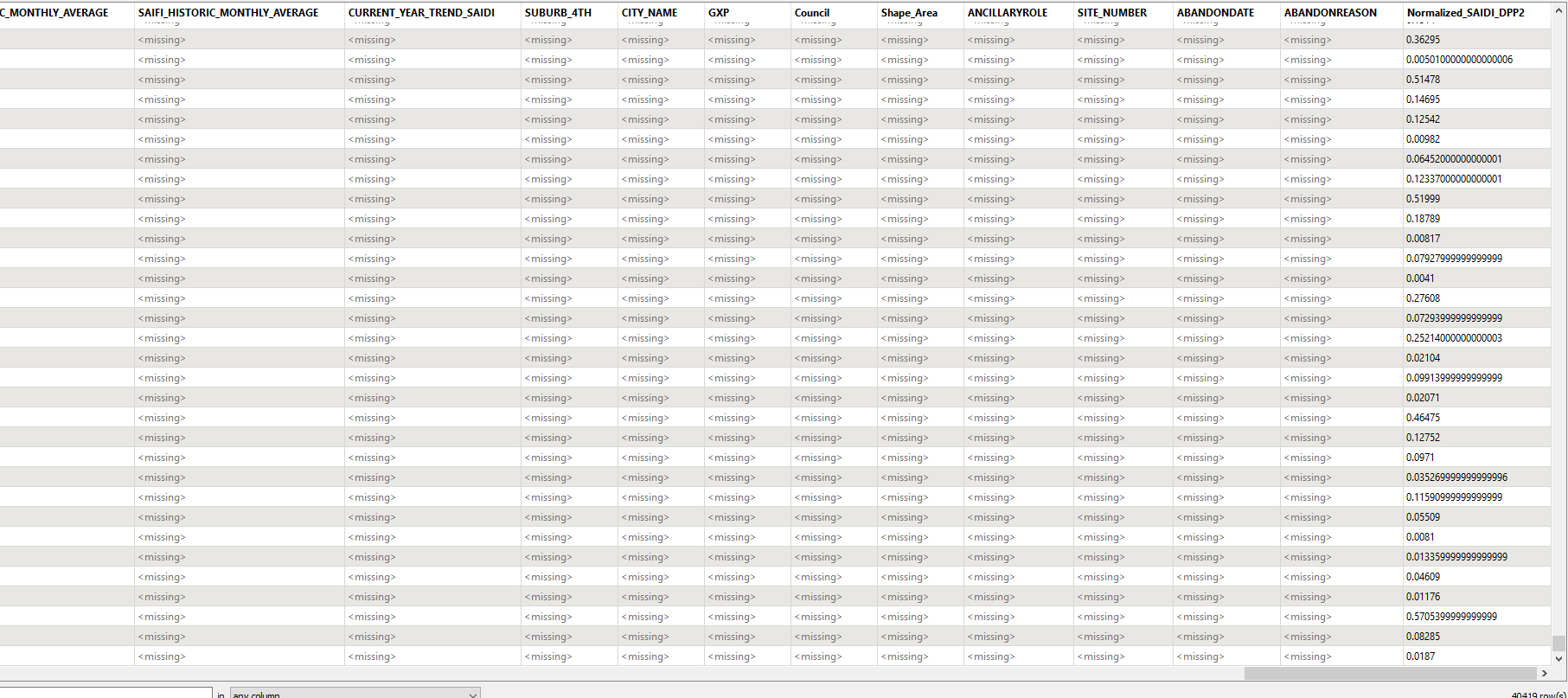
The above code add the attribute in the output but the added attribute is not in-lined with the other attributes of the output. For instance, if the current output has 3 columns, and 100 rows of record, after adding new attribute, it would become 4 column, however, the value of 4th column after 100 rows of record, in the first 100 rows value of new column is missing. Could anyone guide about how to inline the value of new added column with the existing value?