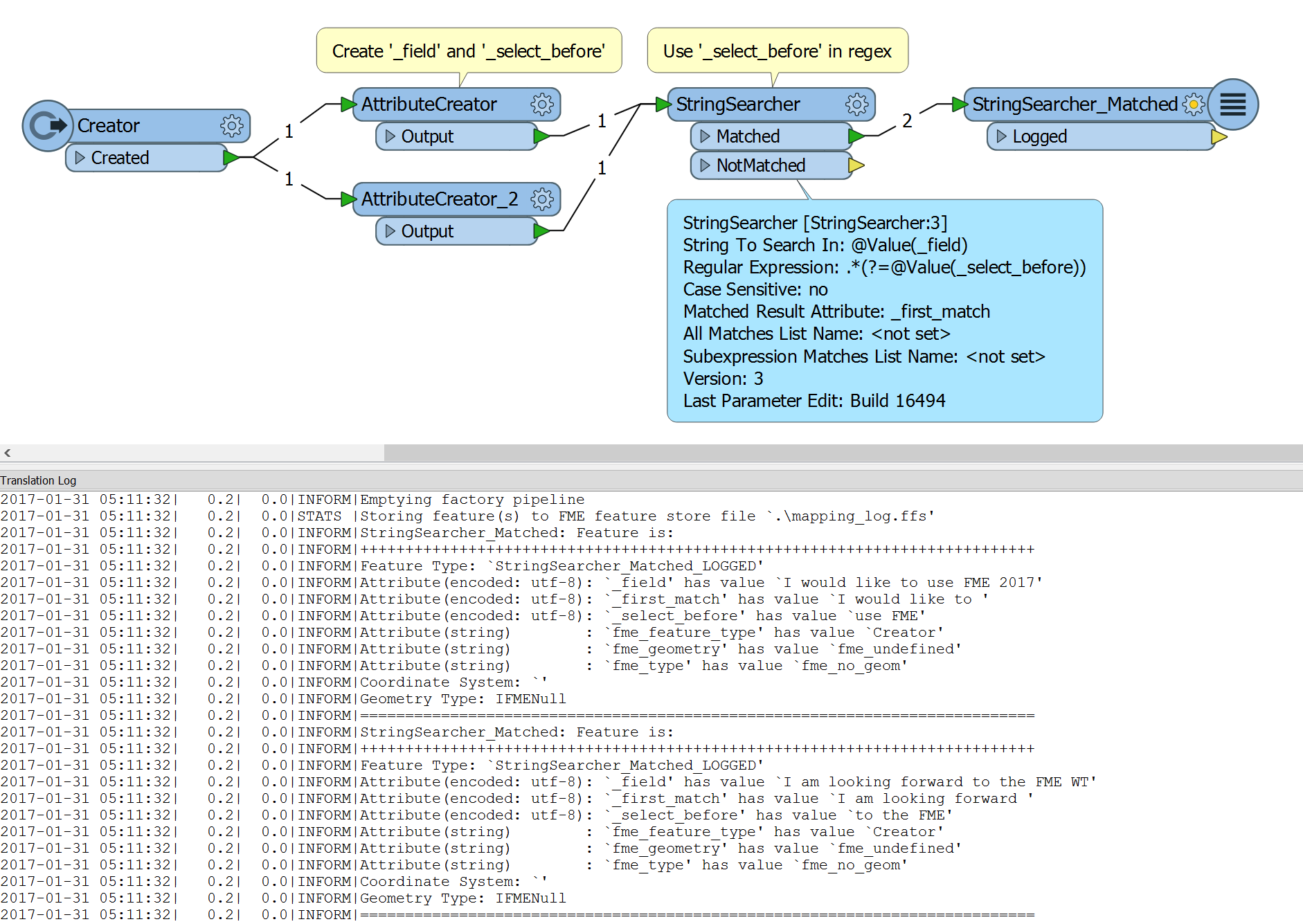
Hi,
This question is similar to the one posted here, however it is slightly different..
I am trying to replace string in a text_line_data attribute where the section of text i want to replace begins with a certain phrase and removes that + everything after it. So for example,
text_line _data:
"I like to use FME 2017"
I would like to identify all text which begin with "use", and delete everything (including that), after it. So, the result would be:
Remain: "I like to"
Removed: "use FME 2017".
The regular expression of ^ only applies to the start of the string, so would only recognize "I" as the beginning of the string.
Is there some way of setting the transformer to find a text string anywhere within an attribute and delete all string after it?