I am looking to split some of the attributes of a filed into 2 separate fields while rest stay in the main field contents. even the split one part goes to separate field and rest stays in.
example I have following data:
Banana 24
Banana 25
Banana 26
Banana 27
Apple 01
Apple 02
Apple 03
Apple 04
Pear
Pear
I want it like Banana stays in original field and 26 goes to separate field.
but nothing happens to pear.
I tried using tester to filter them out then attribute manager with string function to replace but length is not same for all attributes how do I handle different length?
Thank you
Nikki
Best answer by hkingsbury
Thank you for your reply!
it worked partially. This is my real data below. it didn't out the W with numbers for obvious reasons.
how can I place highway numbers or letters separate from kind of Highways.
\s([NSEW]\s\d+|\d+|[NSEW])
this expression is looking for anything after white space using '\s'
the next part is in "()" and utilises OR functionality. a bar "|" means OR, so (a|b|c) means match a or b or c. There are three or statements
[NSEW]\s\d+ - any character from "NSEW" (north south east west) followed by a single space (\s), followed by one or more digits (\d+). HIGHWAY W 123
\d+ - match one or more digits. US HIGHWAY 66
[NSEW] - match any character from "NSEW" . HIGHWAY W
The three parts above all need to be preceeded by white space (\s). That is why the "W" in HIGHWAY isn't matched
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
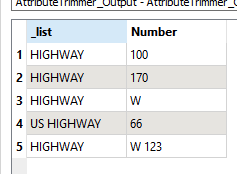
In addition to the solution proposed by @hkingsbury , you can also simply use an AttributeSplitter set to split on a space. Then assign the list elements to each attribute, e.g.
InputAttribute = _list{0}
Number = _list{1}
Number will be set to <missing> if there is no number after the fruit name.
In addition to the solution proposed by @hkingsbury , you can also simply use an AttributeSplitter set to split on a space. Then assign the list elements to each attribute, e.g.
InputAttribute = _list{0}
Number = _list{1}
Number will be set to <missing> if there is no number after the fruit name.
Thank you for your reply! I couldn't figure out how to specify space in delimiter field.
it worked partially. This is my real data below. it didn't out the W with numbers for obvious reasons.
how can I place highway numbers or letters separate from kind of Highways.
I've change tack slightly and instead of using regex to xompletely split the string, use it to just find the "number" and then using the StringReplacer to remove it from the original. See the output below and the process attached
it worked partially. This is my real data below. it didn't out the W with numbers for obvious reasons.
how can I place highway numbers or letters separate from kind of Highways.
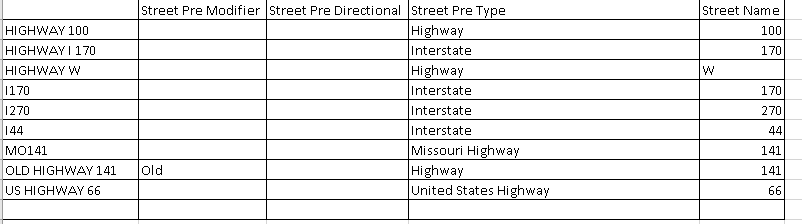
I don't quite understand the nomenclature of US road names (apoligises if this isn't even US data!!) I'm assuming you're wanting to achieve the following?
it worked partially. This is my real data below. it didn't out the W with numbers for obvious reasons.
how can I place highway numbers or letters separate from kind of Highways.
to avoid getting one incredibly complex expression, i think the best approach to this will be to break out the data into discrete branch that you can modify with separate statements.
Use a test filter to filter Interstates, Highways, States into seperate branches, then extract the relevant information for each branch. The logic will be similar for each branch, but will result in a much clearer and easy to manage process