Dear all,
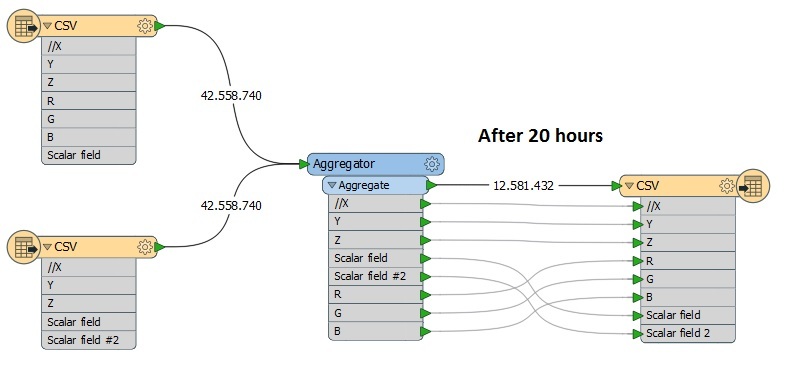
I am currently trying to expand an existing ASCII file with a single row. I have an ASCII file with X, Y, Z, R, G, B and an Intensity (Scalar field). My second ASCII file has the same X, Y, Z and Intensity but instead of R, G and B one single row, named Scalar field #2.
I have both files imported as readers in CSV and connected them with an Aggregator. Now I get an ASCII file which has everything I want: X, Y, Z, R, G, B, Intensity and Intensity 2. My problem is, this task takes +40 hours, since I'm dealing with over 40.000.000 data points each row.
Is there a chance to just copy X, Y, Z, R, G, B and Scalar field from ASCII 1 to a file and extend it with Scalar field #2 from ASCII 2? Do I really have to Aggregate the whole process?
Thank you in advance!