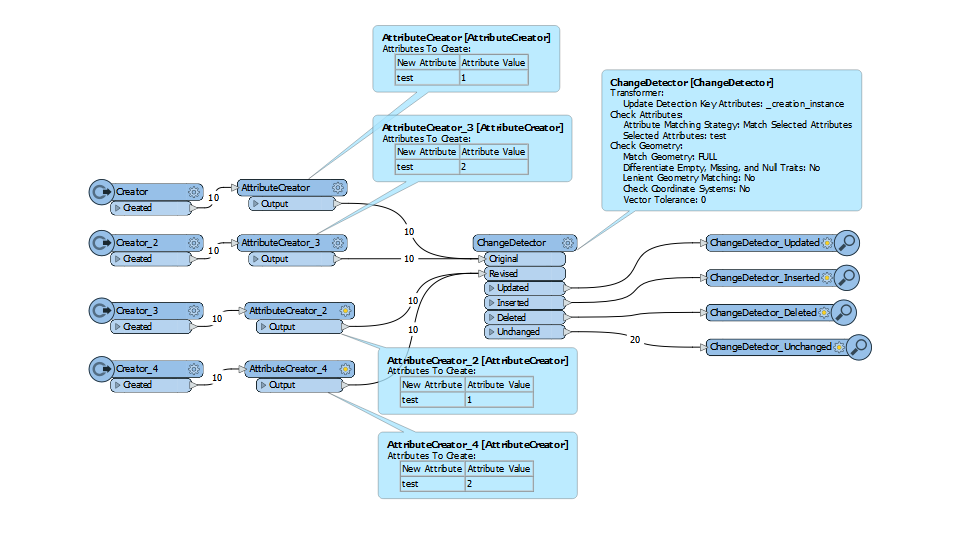
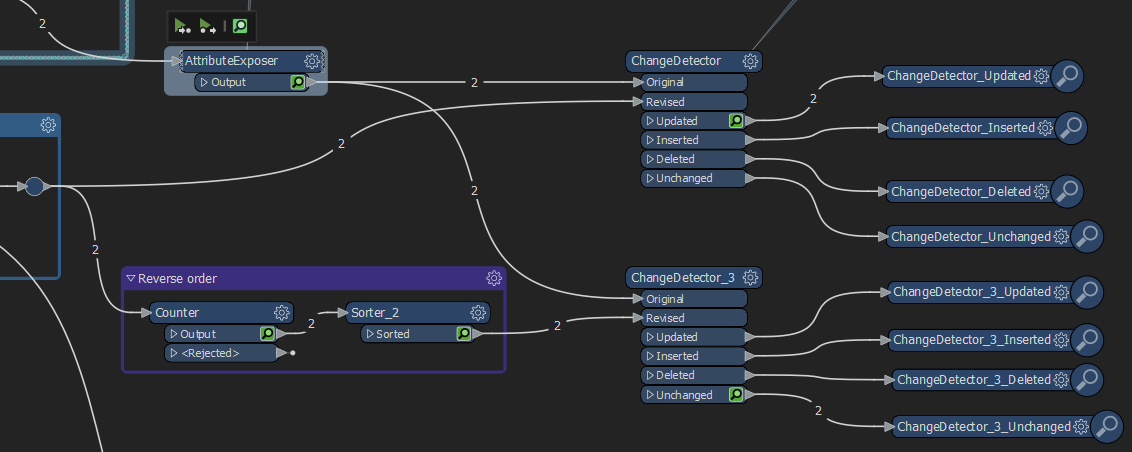
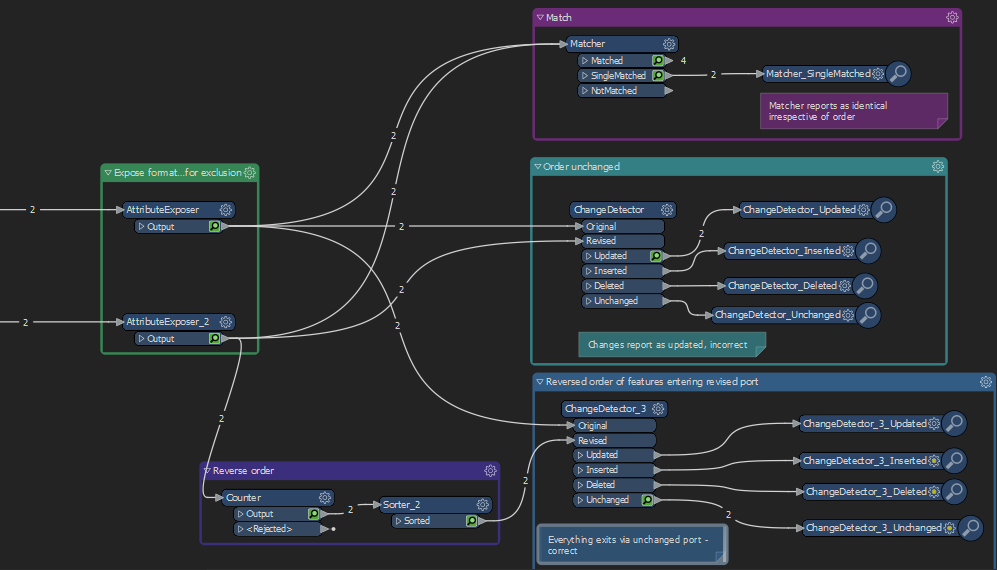
So it will report that 1 change as
originalValue = apples, revisedValue = pears
and a second change as
originvalValue = pears, revisedValue = apples
where all other fields are identical, i.e. if you put them through a matcher you would get no unmatched records
In these scenarios how is the comparison controlled? Does it relate to feature order? In an ideal world, a key value would be unique, but the world is less than ideal.