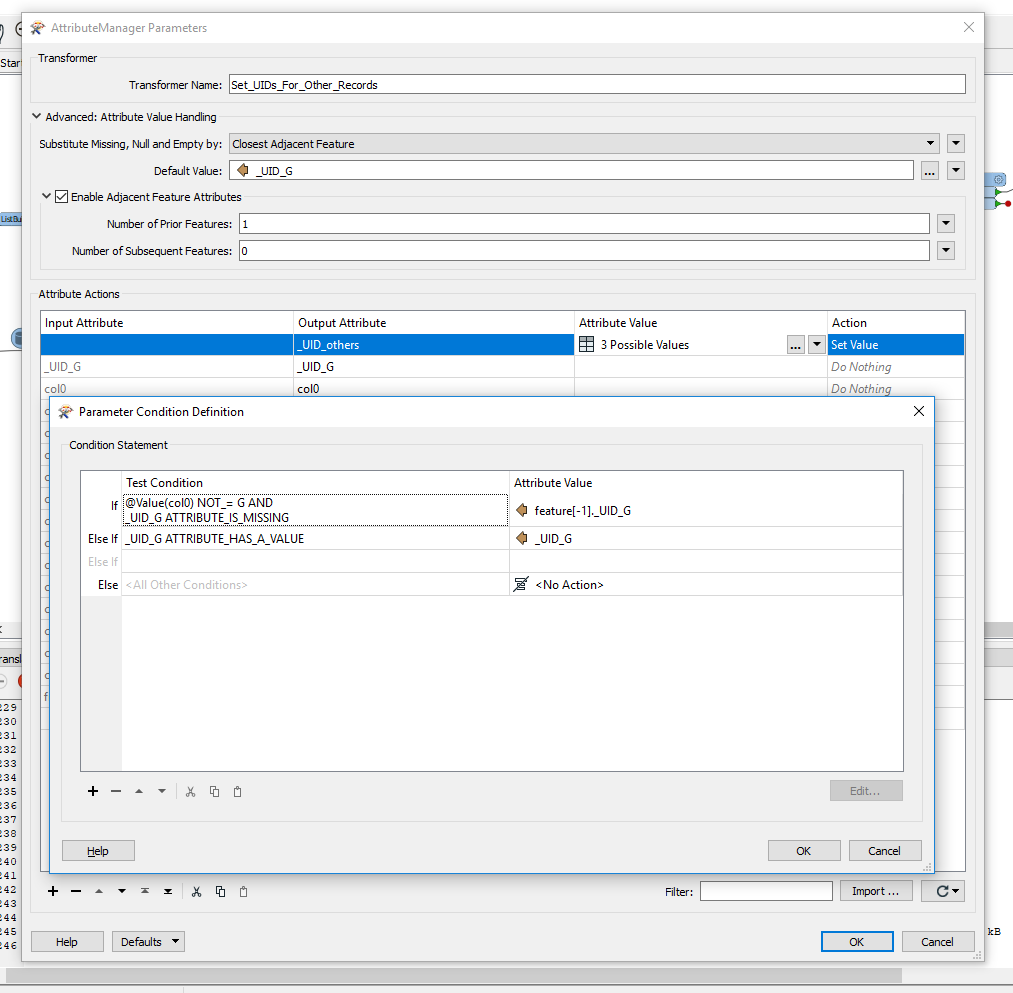
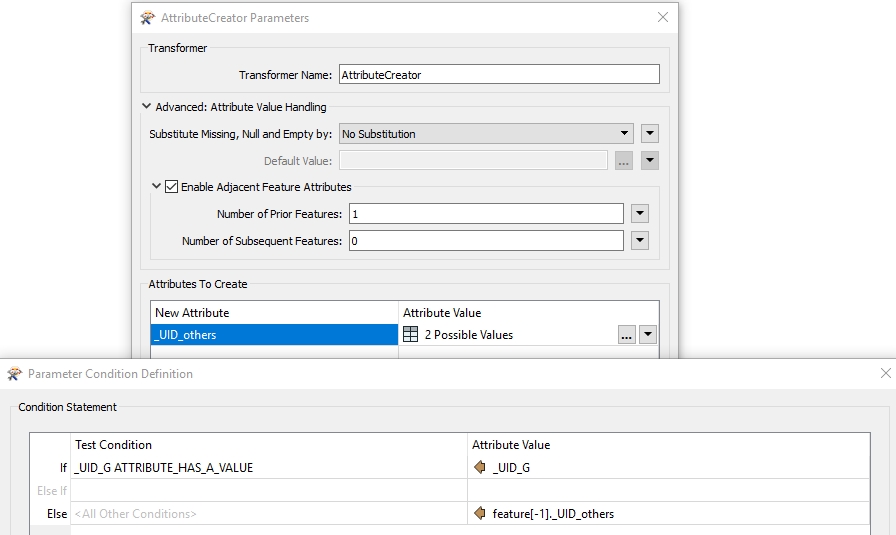
I am trying to leverage the 'Adjacent Feature Attributes' function in AttributeManager to generate a list of unique IDs (UID) for a set of records. In this example I have generated a UID for a single record based on if the record in 'col0' contains a "G" and concatenating the CSV Line Number with 'col2' (this is a timestamp, so I removed the colons to avoid issues down the line).
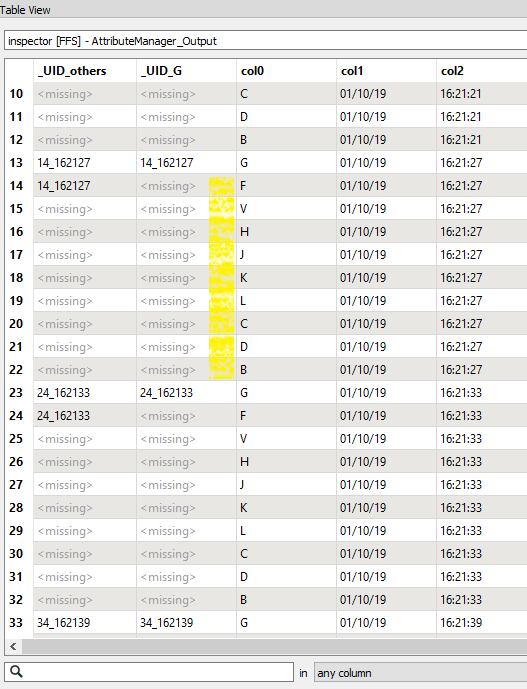
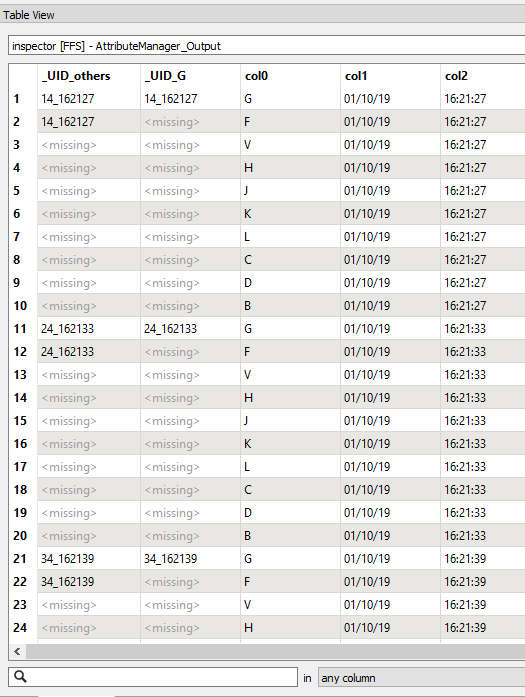
I now want to replicate that _UID_G field to the other records until I hit another 'G' type record to ultimately look like this:
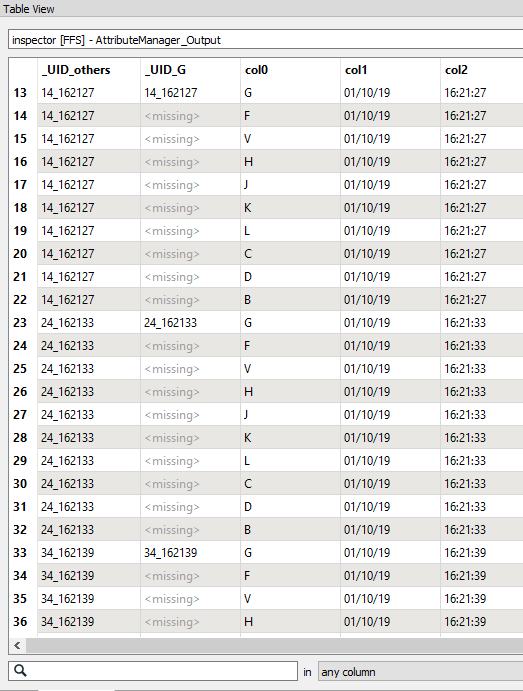
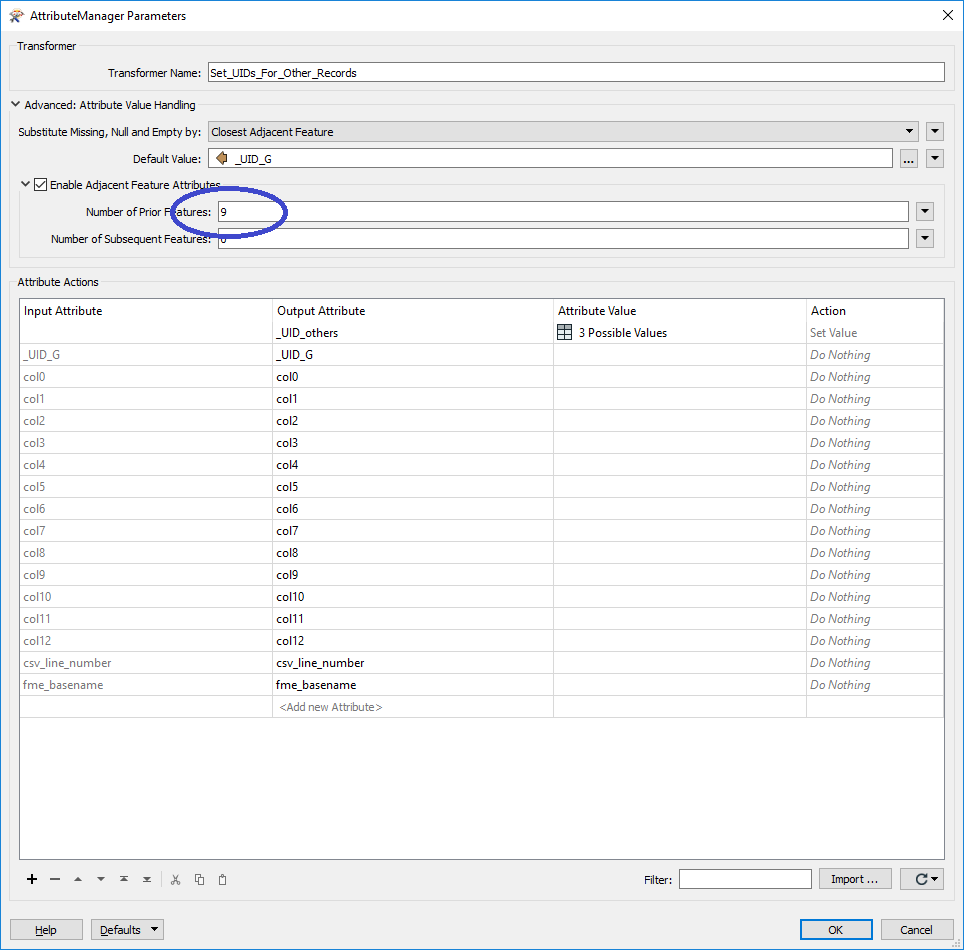
Here is my issue: the number of CSV Lines between records that have 'G' in col0 can fluctuate for each CSV that I run. I am trying to dynamically set the Number for Prior Features in the AttributeManager:
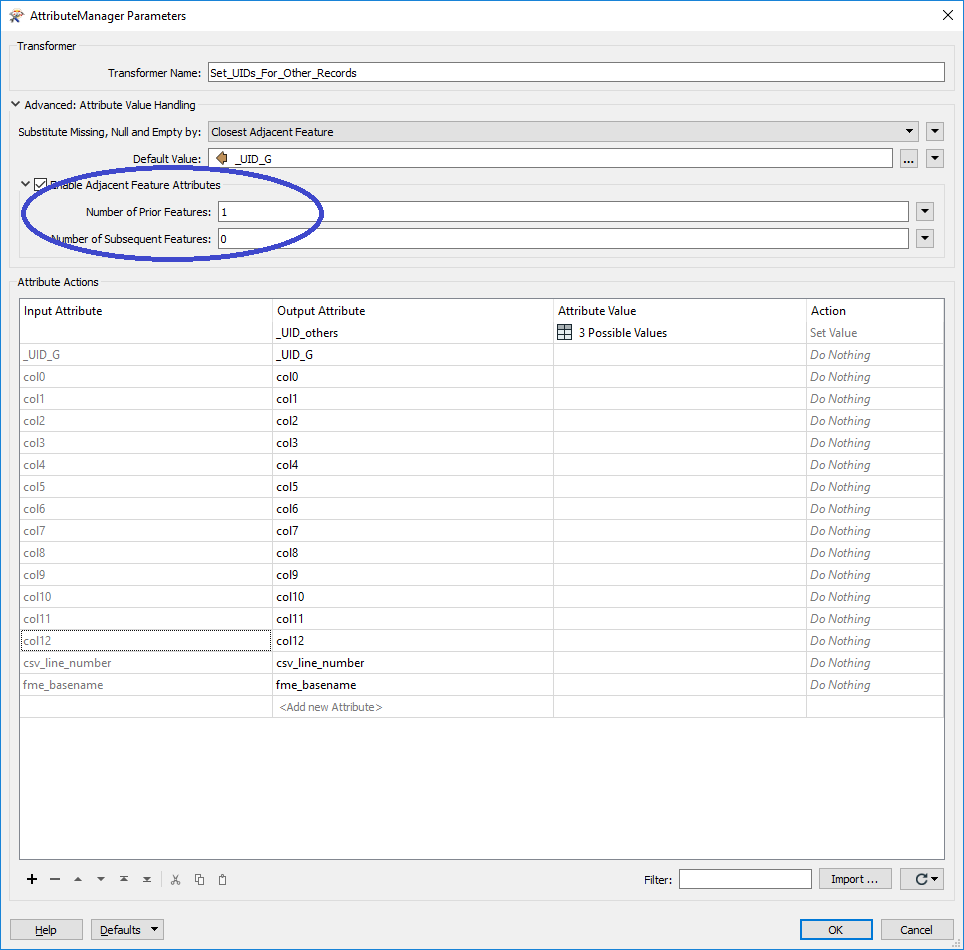
I think I need to build a list from the CSV file I am using first, then figure out how to count the number of records that exist between each "G" feature. From there I can use a TestFilter and address each unique number of records. How can I do this?
I tried ListElementCounter and it returns everything.

In the CSV I am running, there are only 9 records between each 'G' feature. But it could fluctuate between 8 and 12 in other CSV files that I run.
I need this UID to perform joins on data after I define each attribute based on the Letter in col0. Each letter record has a unique number of fields. Is there a better way to do this?
Thanks!