OK S00224 11-18_1-19.csvI have a list that I need to parse. I am not very well versed in Regex. I can manually build my attribute names (and in fact will have to change some of these as they are. I need to know how to
1. handle the different number of dashes between the attribute name and the attr value.
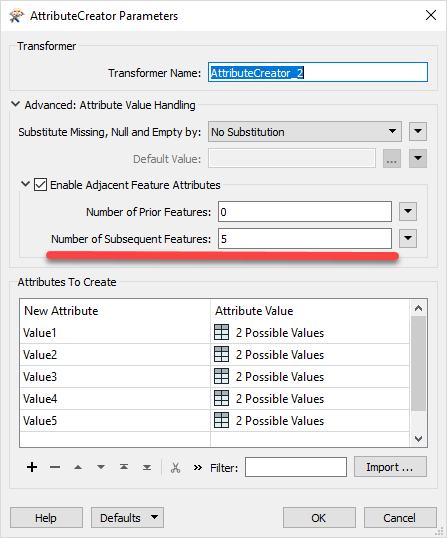
2. retrieve multiple attributes from one line.
3. remove the brackets and write the value to the attribute with varying length strings
4. handle LF
5. manage dashes inside of brackets (keep)
Here is some of the data structure of the list...
RKORT 1712 OKOCS 11/01/18 11:33:07 18110111301739 UPDATE
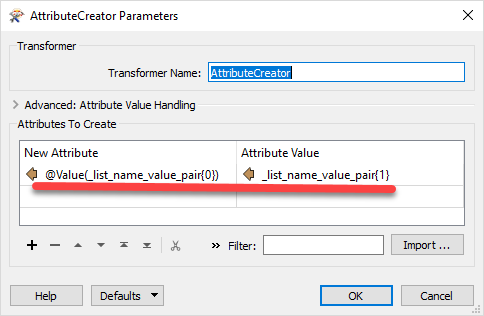
TICKET NUMBER--[18110111301739]
OLD TICKET NUM-[18102215173653]
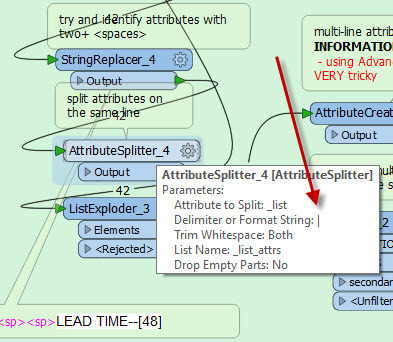
MESSAGE TYPE--[UPDATE] LEAD TIME--[48]
PREPARED------[11/01/18] AT [11:30] BY [IMTHEBESTMAN@TRUCKERCONST.COM]
CONTRACTOR--[MTRUCKER CONSTRUCTION] CALLER--[JARVIS BESTMAN]
ADDRESS-----[707 S CREEK COUNTRY ROAD]
COUNTY-[PINE] PLACE--[CUTHING]ADDRESS-----[] STREET--[E][DEEROCK][RD][]
NEARBY MAJOR INTERSECTION-[N LITTLE AVE AND E DEEROCK RD]
LATITUDE--[43.014899] LONGITUDE--[-166.761132]
SECONDARY LATITUDE--[43.017155] SECONDARY LONGITUDE--[-166.758085]ADDITIONAL ADDRESSES IN LOCATION--[N]
LOCATION INFORMATION--[7:34:18 - PIPELINE - FROM THE INT OF N LITTLE AVE AND E DEEROCK RD, EAST]
[ON E DEEROCK RD 0.41 MI, NORTH 0.10 MI ONTO UNMARKED ROAD -- LOCATE 120 FT]
[EAST, 211 FT SOUTH, 126 FT WEST, 200 FT NORTH AND EVERYTHING WITHIN -- MAY]
[BE A GATED ENTRANCE]