That's an excellent question, because whenever you duplicate transformers like that there is normally a better way to do things.
However, I think this case is the exception to that. A different where clause would effectively give a different lookup table per feature, and that isn't something the transformer is designed to handle.
Interestingly... the SchemaMapper appears to be feature based; a feature that enters then emerges immediately, not waiting for other features. So it might be possible to create a workaround.
I would suggest trying:
- Create a second output connection from the Input port to a FeatureReader
- Use the FeatureReader to read the data from the database table using the required where clause (which can be defined as an attribute).
- Use a FeatureWriter to write that data to a plain lookup file (like CSV or text)
- Then have the SchemaMapper point to that CSV file as the lookup source
- Finally set the connection runtime order so the FeatureReader/Writer are triggered first
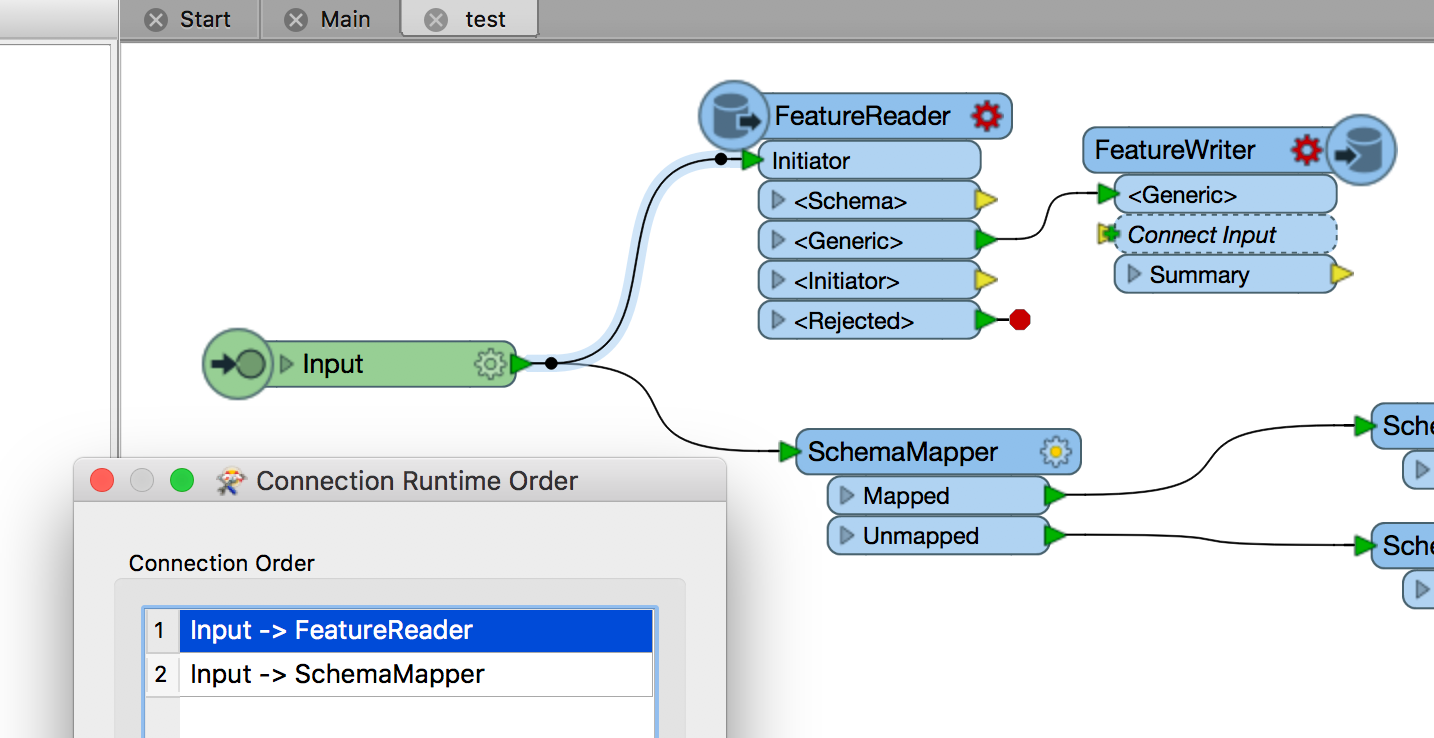
What I hope happens is that each incoming feature goes to the SchemaMapper, but by the time it arrives the CSV data has been overwritten. That way it gets the unique lookup table you want.
I don't guarantee that will work (it might just cache the lookup of the first feature), and you might not consider it worth the effort trying to set it up (it's a fair effort for little payoff), but if you're inquisitive then that's what I would try first,
Hope this helps
Mark










")

















