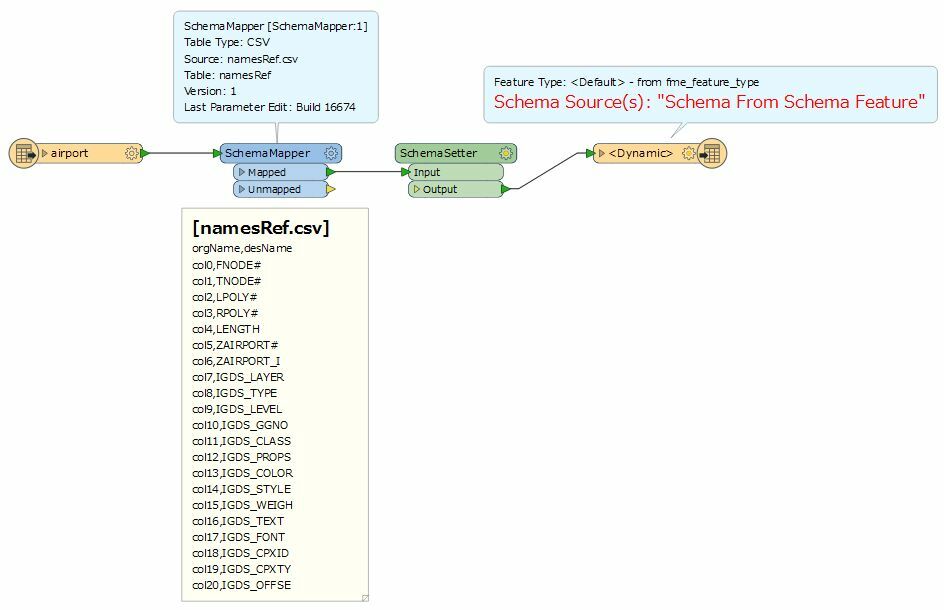
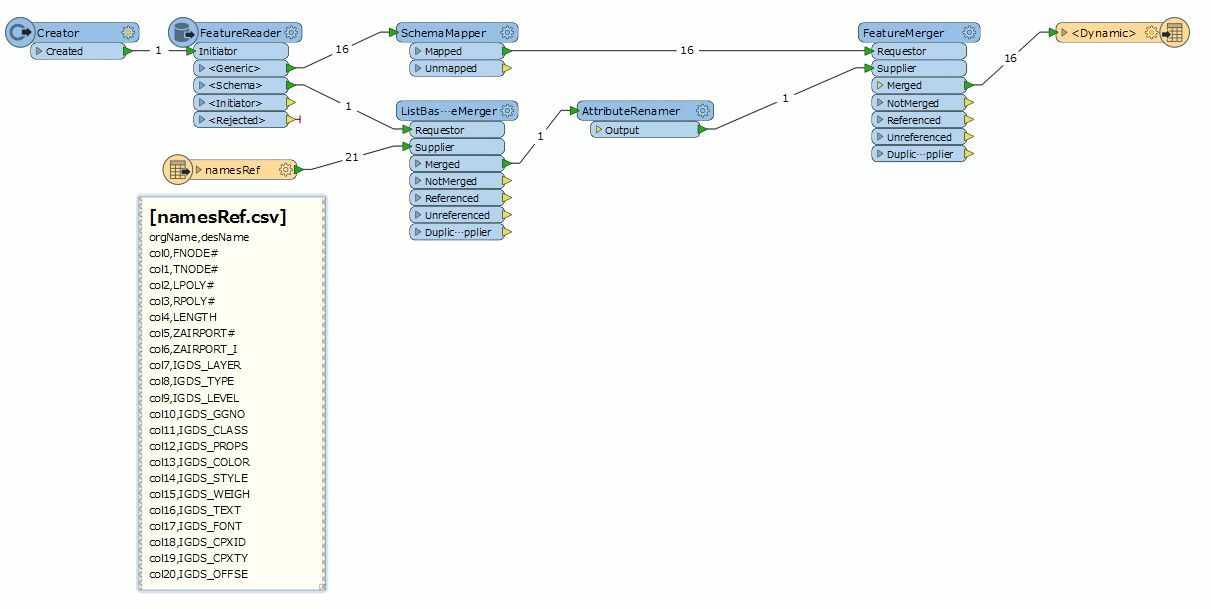
Because I have hundreds of tables to process, many with more than 20 columns, I wanted to use dynamic schema with my writer dataset to quickly reproduce the database in the destination format with the appropriate structure for each table (i.e., I don't want any unnecessary columns in each of my tables). Unfortunately, I can't find a way to rename the columns and still use the schema from the source database.
I don't think that FME can handle both renaming attributes and dynamic schema in a single flow. I was wondering if anyone had any ideas, or to just let me know that I'm wasting my time.
Thanks!