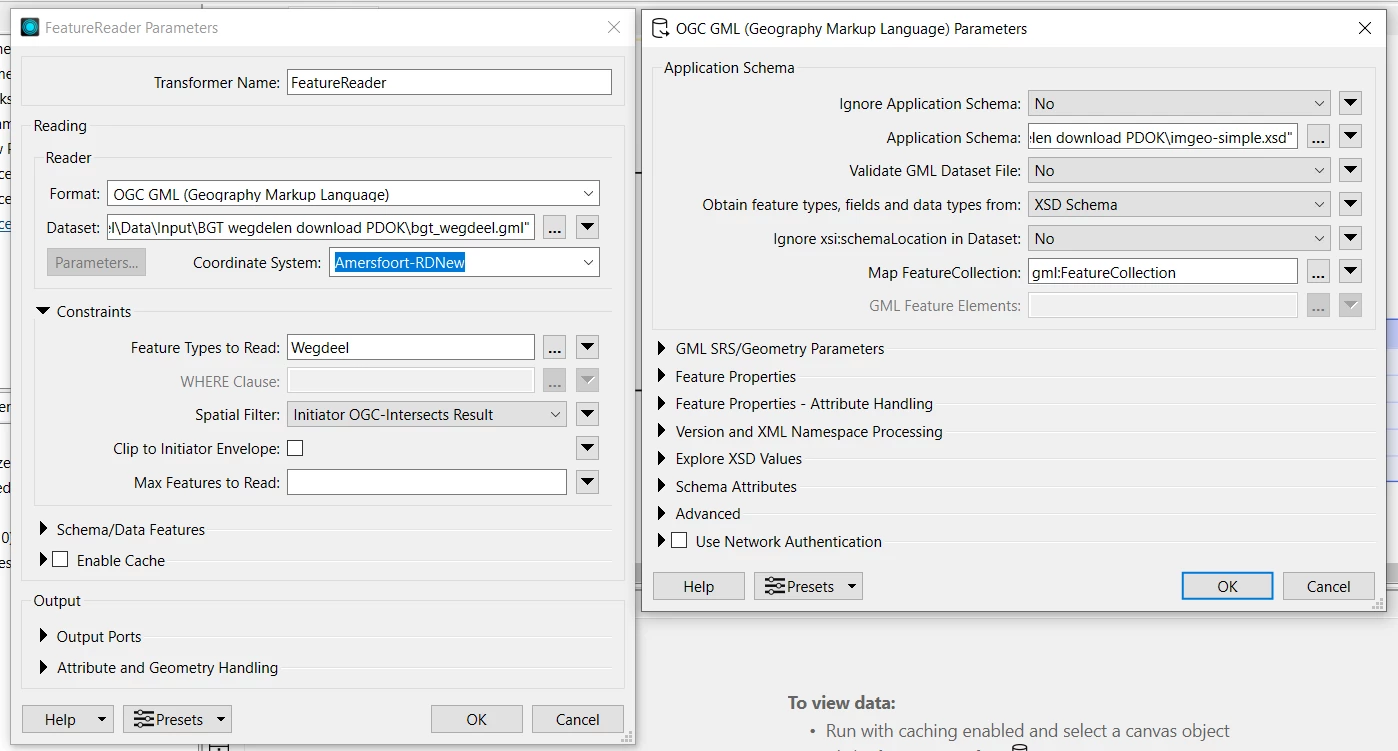
Normally I use FeatureReader to import my datasets. This time I am dealing with a 4.5 GB GML dataset.
What are the best settings to improve reading speed for my FeatureReader? Just like a general approach to use, reading GML file is just an example. I also other formats like .gdb, xml, json etc.
I try to use the SpatialFilter when possible which makes the reading already more targetted. Hence, its switched this time also using my study area as Initiator.
Page 1 / 1
A 4.5 Gb GML file is going to be slow ¯\_(ツ)_/¯
If possible, try not to have it on a network drive, but locally, preferably on an SSD
If you’re planning to read from this GML more often, I would recommend transforming it into a spatial database format first (PostGIS, for example) and read from that. Or consider using the BGT Downloader custom transformer by @koen_verhoeven (https://hub.safe.com/publishers/terralytics/transformers/bgt-downloader)
Thanks Hans for your reply, in this case I am more curious in general how to speed up the FeatureReader. Specifically for BGT the BGT api which is probably included in the nice transformer you shared will be best.
Maybe there is some settings in the FeatureReader I could use to speed up the reading process? SSD drive is a good idea, will try that one for sure.
My general advice (might not be applicable for your situation) is to read in the least amount of data possible.
Make use of where clauses, remembering you can make these dynamic and construct them using attribute values
For spatial data, make use of the spatial filtering ability of the FeatureReader
Could it be faster to periodically preprocess the source data into a more performant schema/format?
I think what is important, or helpful to know is when a format uses indexes and what types. Any text based formats like GeoJSON, XML/GML don’t (usually) have an index. So a spatial filter or even selecting the number of features to read have very little to no effect on performance. As I understand it FME still needs to actually create the features in order to do the spatial check on them. There may be a litte more smarts though under the hood with FME’s GML reading. For example if a spatial filter is used will FME skip out creating the attributes and only create attributes in the case where there is a spatial match?
Compare that to a database which has been nicely indexed or even a shapefile with it’s external file indexes, the FeatureReader will be able to leverage these indexes to speed up reading dramatically.
You can see from a formats quick facts if Spatial indexing is used: https://docs.safe.com/fme/html/FME-Form-Documentation/FME-ReadersWriters/gml/quick_facts_gml.htm. This isn’t always helpful though because there are some formats (like GeoTiff) which FME lists as not having a spatial index, however, due to the nature of the format, reading with a spatial filter is almost always faster. I’m sure there are likely also cases when a format does have a spatial index but for whatever reason FME struggles to support it properly.
I think in general though, using a spatial filter like this, is super helpful even for formats which don’t use indexing, if only to reduce the amount of features which need to get cached.
Typically when working with spatial GML data it’s really helpful to tile the data and include the grid index and tile size in the file name. This way you can use the filename as a bit of a filter. This of course comes with it’s own headaches - for example clipped features which need to later be stitched together.
@virtualcitymatt how about these 2 features. Does it make sense to use them, and for which cases?
@virtualcitymatt how about these 2 features. Does it make sense to use them, and for which cases?
I’ll be honest I haven’t actually used the Enable Cache option but I can 100% see it being helpful. If you are always working with the same data then this will most likely speed up the process a lot. What I’m very unsure of though is what gets cached. For example if you have a spatial filter of area x and then you have another spatial filter of area y which doesn't overlap what will happen - does the data get cached pre or post filter. This would be a good test.
As for Schema/Data Features I’ve certainly used just data features before to skip outputting a schema features. I feel like it was faster just outputting data features and Schema Features as well but it was a few years ago now that I played around with this setting. In general if you’re not working on a dynamic workflow I think you can skip the schema feature.