Hi,
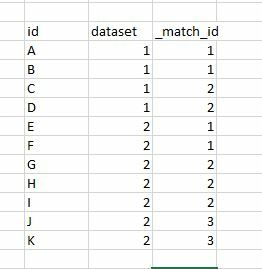
I have two datasets of line features which I want to check individually for duplicate line features. However, the output containing the duplicate line features of both datasets should be combined in one dataset. I used a Matcher transformer on each dataset. When combining the output I of course get similar match_ids for features, that aren't always matches of each other. How do I adapt my workbench to avoid this?
Is there a way to set the match_id attribute of one of the Matcher transformers to start counting at a specified number?
I also can't send both datasets to the same transformer, because for my datasets that would result in unwanted matches.
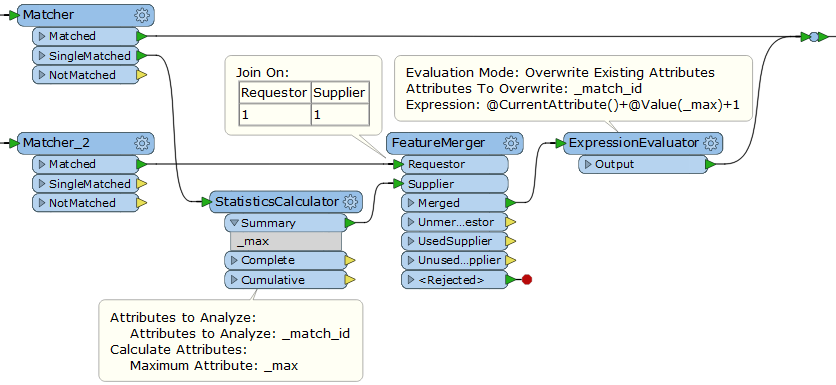
a simplied version of the workbench
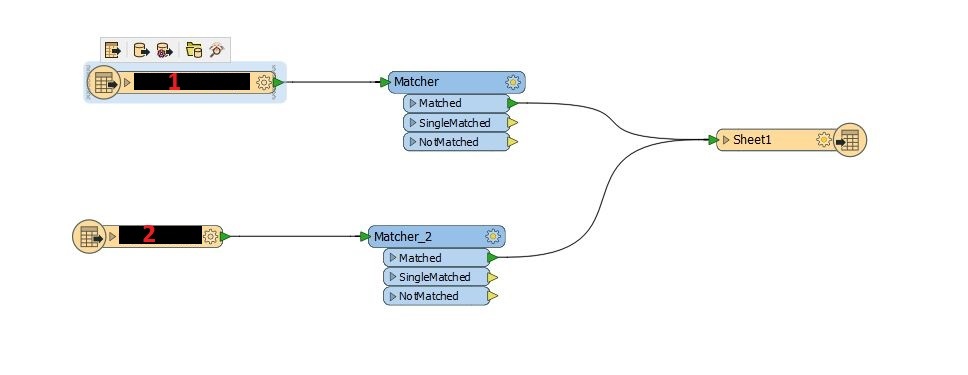
And a simplified version of the generated output