FME server doesn't create log for failed workbench
We have a server running many jobs and one of them normally runs successfully and a log can be reviewed but at other times the job fails and when i access it i get the message Error: The log file for job ID "######" does not exist.
I’ve seen the post in FME Server 2019 Error: The log file for job ID "2613" does not exist and we have plenty of disk space, the job frequently works successfully, other jobs are still creating log files. I’ve checked all the suggestions in that post.
The failed job is recorded as running for a couple of seconds but without the log I have no insight into why it is failing
Page 1 / 1
How are you triggering the job? I’ve had similar issues when a scheduled job runs, but couldn’t view the logs. Manually running it through Flow then alerted me to a custom transformer missing
You need to look at the “Result Data” on the Log page, as it will likely explain that the process has not started for a reason (and thus why the log hasn’t even started to be created)
How are you triggering the job? I’ve had similar issues when a scheduled job runs, but couldn’t view the logs. Manually running it through Flow then alerted me to a custom transformer missing
Hi
I don’t think anything is missing, this job normally runs to completion but when it doesn’t there is no log. The job is triggered through an automation, when i submit it manually it works - but then that is the norm anyway.
You need to look at the “Result Data” on the Log page, as it will likely explain that the process has not started for a reason (and thus why the log hasn’t even started to be created)
This is running in server, there is no “result Data”, indeed no log at all!
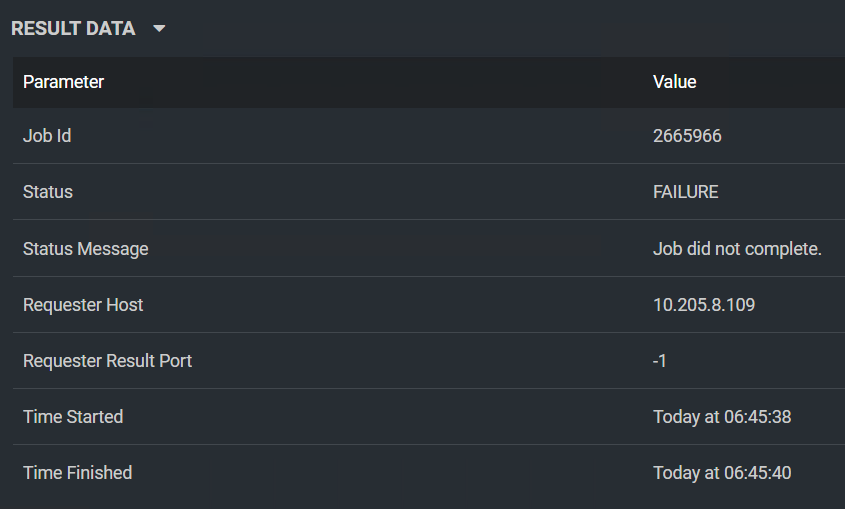
Result data is part of the log page in FME Flow, rather than part of the log file. For instance:
Result data is part of the log page in FME Flow, rather than part of the log file. For instance:
Thanks for that, it doesn’t give much away….
And the log file doesn’t exist on disk
Now raised with Safe support. Engine is failing at the same time but not for every job submission
I’m seeing the same behavior. I have an automation that runs every 5 minutes and sometimes it fails but there’s no log file created.
Folder where logs are saved - notice the missing file for 62491
I’m seeing the same behavior. I have an automation that runs every 5 minutes and sometimes it fails but there’s no log file created.
Folder where logs are saved - notice the missing file for 62491
When we looked in the server logs there was a corresponding engine failure and I was offered a potential fix by SAFE….
“By setting these parameters to 1 the jobs will restart after every run. This can lead to a clean engine and prevent any issues with previously loaded dll's and Python interpreters. The restart of the engines should take less than a second. Even if this isn't a long term solution it would be great if we can test this to refine the issue. In: C:\Program Files\FMEFlow\Server\fmeServerConfig.txt MAX_TRANSACTION_RESULT_SUCCESSES=1 MAX_TRANSACTION_RESULT_FAILURES=1”
We have a very busy server and obviously there is an overhead in this as the engine restart takes resources. However I did try it and setting the parameters to 1 seemed to fix the problem but according to the logs this added about .5s to the task. Reverting the parameter values caused the failures to reappear.
Ultimately the failing job was doing a huge amount of work at startup with many readers and filtering in the workbench. I replaced them with SQL Creators with quite complex but efficient SQL to pre-filter the rows and reduce the read overhead considerably. Not only did the issue disappear but also the workbench ran considerably faster.