Hi there. I am a FME beginner and have a simple question regarding constructing a SQL statement.
My goal is to use FeatureMerger to merge CSV table data with polygons. But this process is going to be a dynamic process, I want to create a flexible workspace. For example, I want to use different CSV input files but the rest of the process stay same.
Here is my question. I want to use one of output value from a transformer in my SQL statement. How I can do that? I described my workflow below.
1. There are a CSV file that has a join key field (in the image below it is called "area") and polygon data (join key name in this polygon is called key_code in the image below). This CSV data include lots of duplicated join key values.
2. In order to use FeatureMarger between the CSV data and the polygon layer, I wanted to get a unique join key values from the CSV table. I used DuplicateFilter and Aggregator to get a comma separated join key values to use in a SQL statement later. At the end of process 2 in the image, I obtained a value like following.
33946011,533946012,533946013,533946014,533946021,533946023,533946111,533946112,533946113,533946114,533946121,533946123
3. Then, I set up a connection to my PostgreSQL database.
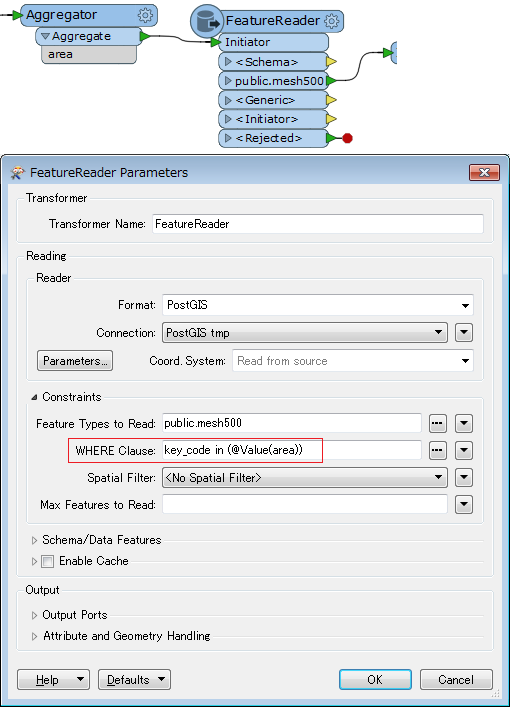
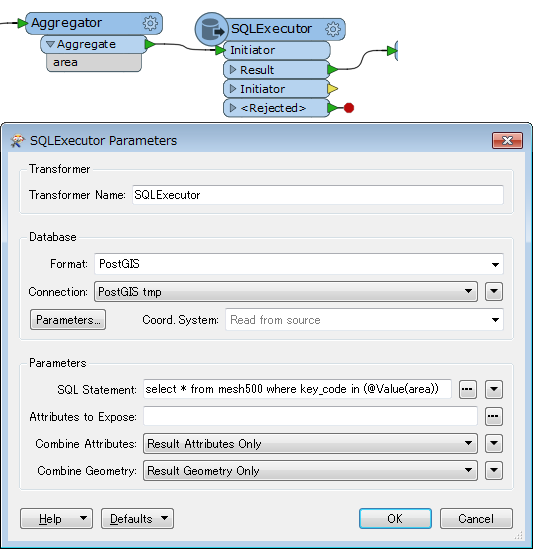
4. To limit the number of features to load (there are more than 2 million polygons), I want to set up a SQL statement to just read features which have the same join key values as the CSV table. So, I wrote SQL statement like,
Select * From mesh500 where "key_code" in (XXXXXXX);
Now, I want to insert the aggregated join key value (33946011,533946012,533946013,533946014,53....) to the above SQL statement (XXXXXX part).
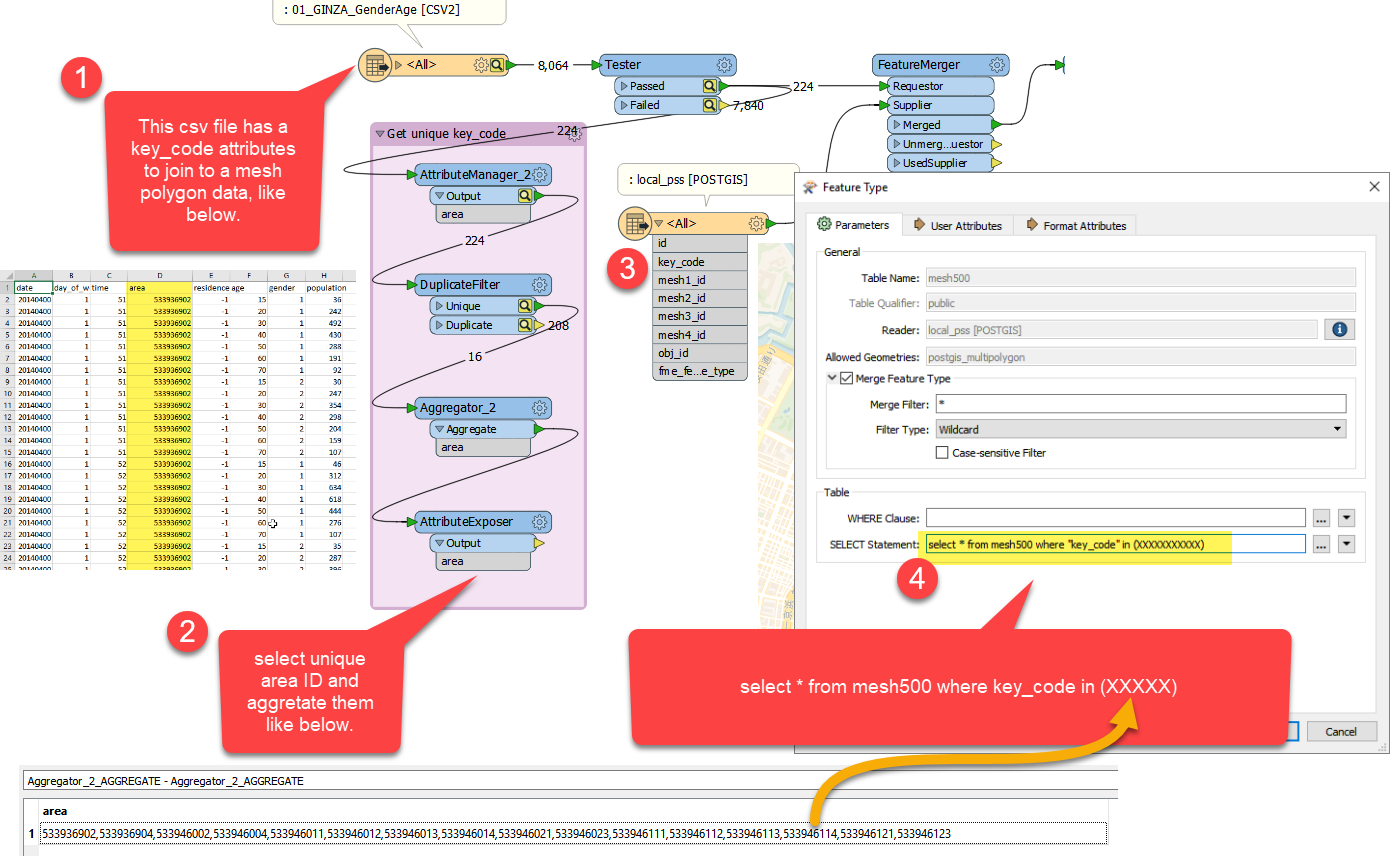
Someone who know how to do this, please please let me know. I tried a private parameter to store the unique key values but it didn't work in the SQL statement. It looks simple but I cannot figure out.
Thank you in advance.
Hiroo