


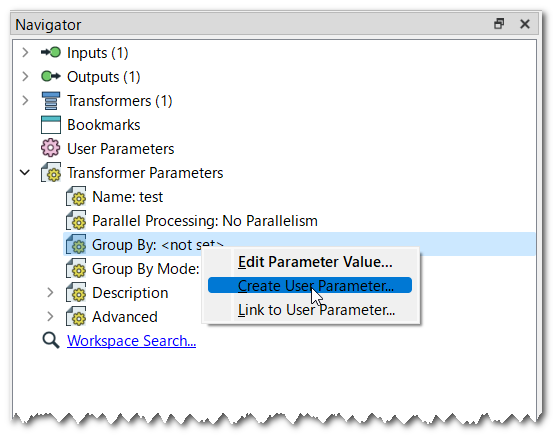
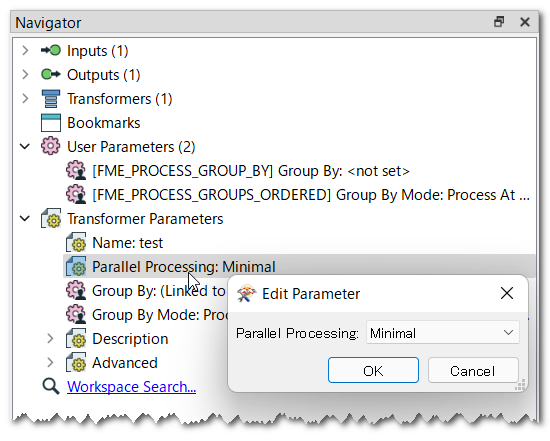
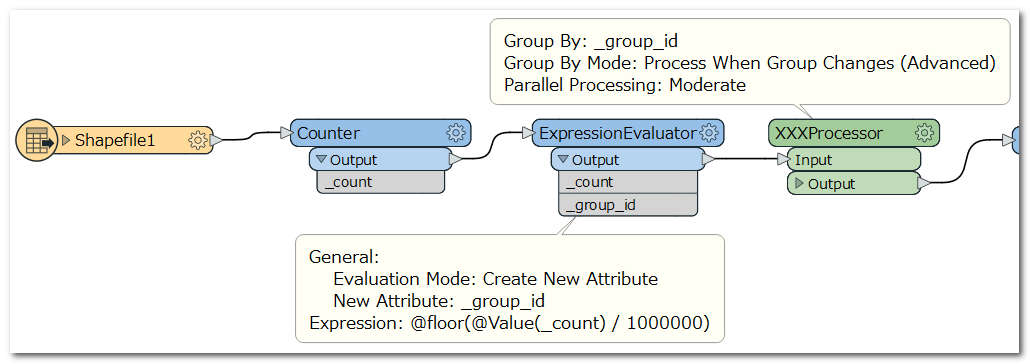
Suppose I have a data containing 10 million records but I want to read every 1 million features and run my processing parallel in 10 batches. Can someone please suggest any method?

Question
How can we read and process the data in batches of say 1 million records ?







Reply
Rich Text Editor, editor1
Editor toolbars
Press ALT 0 for help
Helpful Members This Week













Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.