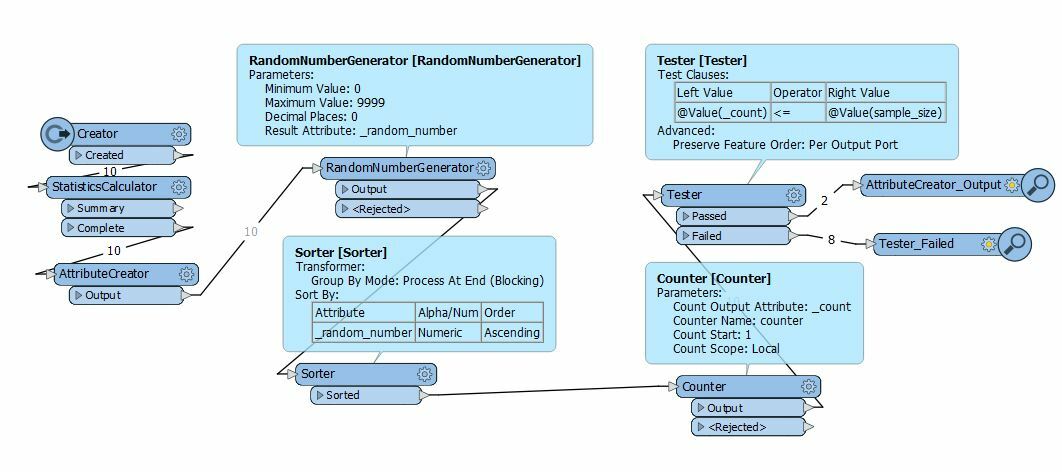
The basic workflow is:
- Read in features
- Count them (via StatisticsCalculator, Total Count)
- Depending on count value, calculate sample value
- Random sample features based on calculated sample value
Sampler doesn't allow to set Sampling Rate (N) as attribute value. Maybe there is a workaround?