Hi FME'ers,
In an hour or so we're starting the webinar on Choosing the Right Transformer (24-May, 10am PDT). Several users already submitted scenarios where they are facing a challenge finding the right transformer, and Dale, Iris, and I will try and live-build a workspace to solve their issue.
At the same time, we had a few scenarios that we won't have time to cover in full, and wanted to throw them out for your suggestions. So, if you think you know what transformers to use in the following scenarios, or if you have a brief scenario that we can try and demonstrate online, please let us know in the comments below.
We'll do our best to work this content into the webinar to make it really live (and quite exciting for us presenters!) - and if you have any comments on the webinar or suggestions for the challenges we are showing, do also let us know.
Cheers
Mark
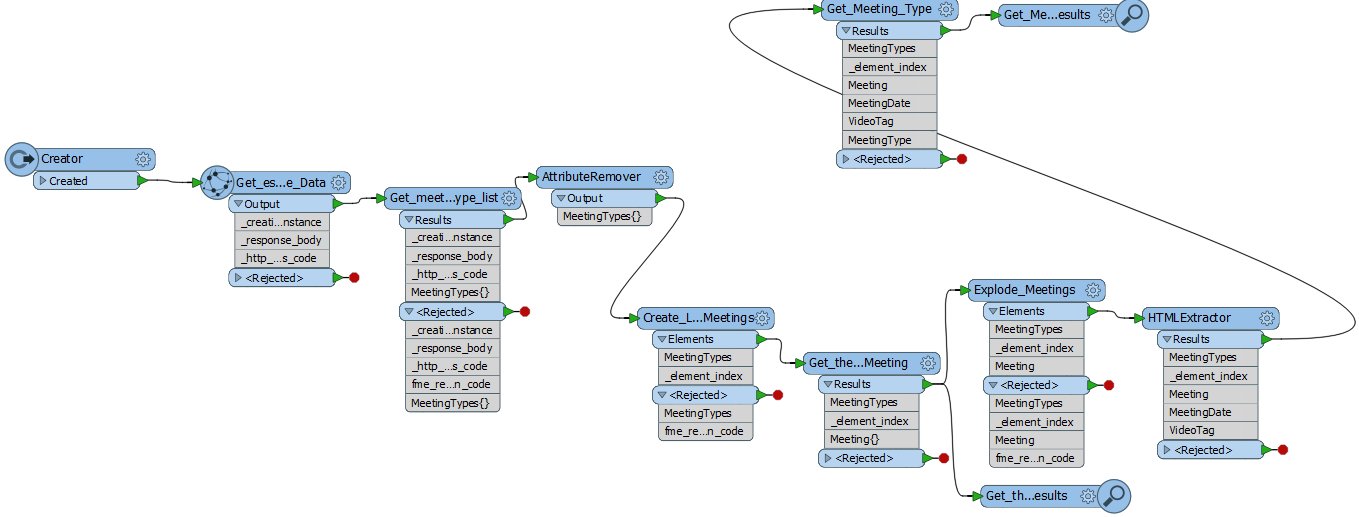
Scenario 1: Given this feed of live cycle data from TFL (Transport for London), which transformers would you suggest to read the data, to create point features, to remove extra attributes, and to add/update XML metadata using a specific schema? Is there a specific technique that you can recommend?
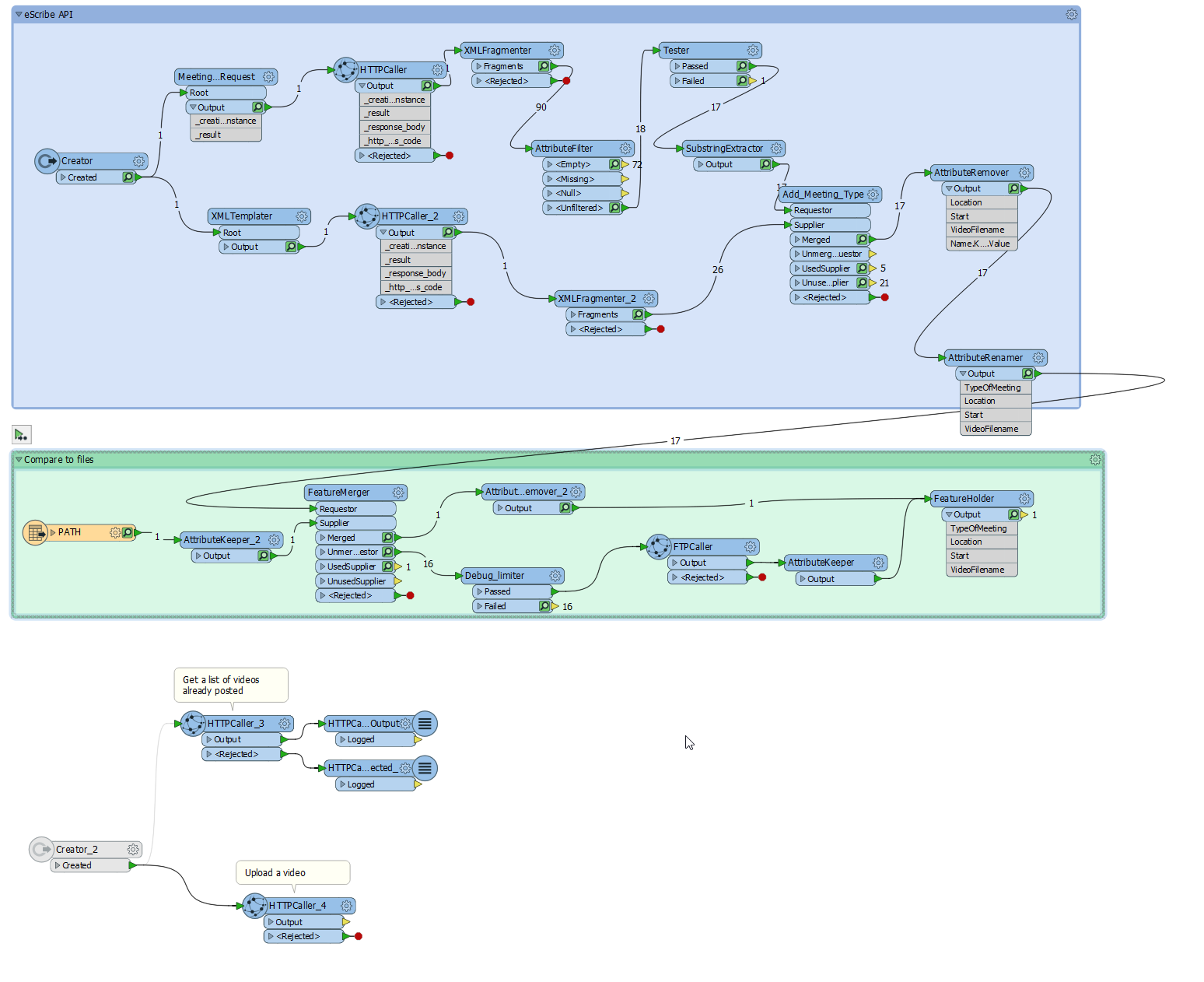
Scenario 2: Given a webpage (no demo available unfortunately) with a list of video files, which transformers would you suggest to download each file, compare it to a list of existing files, and (if new) publish it to a YouTube channel? What other files could be published using a Google API?