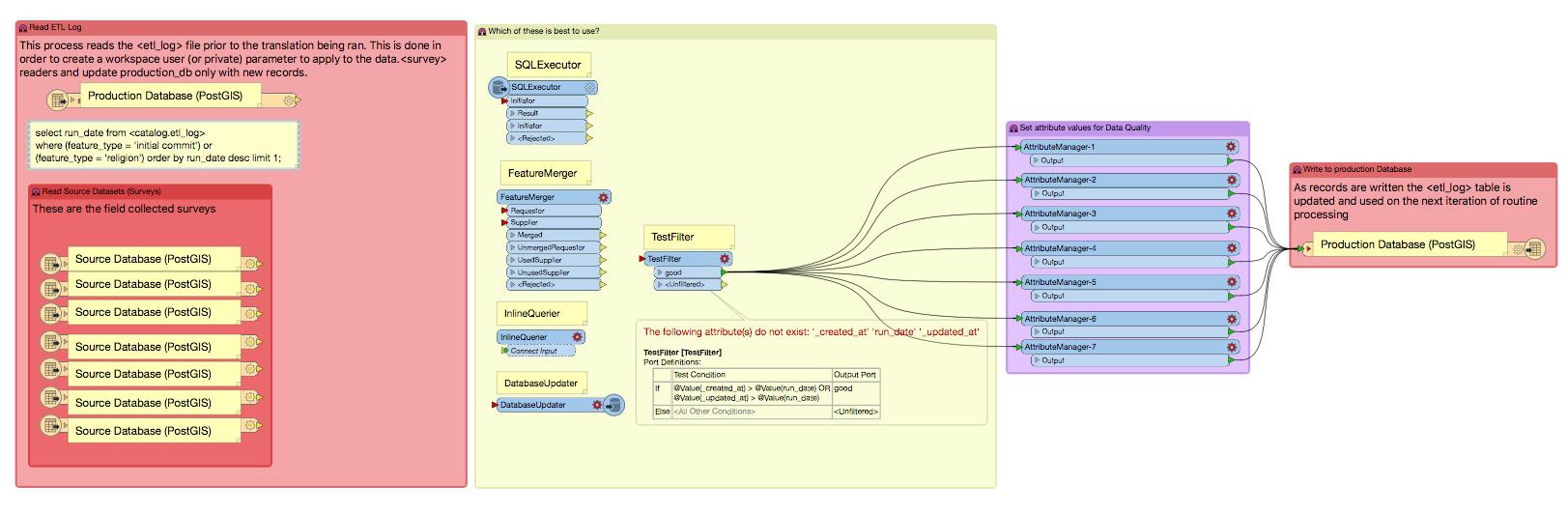
I am trying to set a published workspace parameter(s) to automate an ETL routine that reads multiple tables from one PostGIS DB to incrementally update another single table in a separate PostGIS database. The simple workflow is something like this:
a) Multiple tables from a PostGIS database are read and concatenated in another separate PostGIS database table representing a single canonical theme of these records. These themes classify certain field collection survey records into a meaningful, single common theme.
b) The second database does have a function which writes the id, feature_type and a run_date to an etl_log table each time the routine processes. I'd like to use this automated output as an input value each time an update routine is called on the server. I've tried to work in a SQL SELECT statement that filters only those records that have a created_at or updated_at attribute greater than (or after) the run_date and label those as "good", passing through to the write phase of the routine. I've only had success in running on single instances of tables, using FeatureMerger and TestFilter transformers.
c) I want to automate the update process which could be run weekly or monthly, in order to update only those feature records that have changed or are new since the last time the ETL routine processed records. So it is a database updating process, but requires a global environment parameter saved somewhere that can be called and triggered when the next instantiation of the routine is run (I think).
d) Where can I put a workspace parameter to trigger this update routine to only extract and load those records into the table that are after the last run date? I've researched SQLExtractor, FeatureMerger, and InlineQuerier but can't quite find the solution.
e) I'm prototyping these workspaces in Desktop but will eventually publish to an FME server instance after proofing the routine works correctly. There are several of these routines creating different classification themes in the production database, but the source survey tables come from teh same database.