
A bit of a subjective question, but what are fast file-based geospatial data formats to read in FME?
I have a set of geodatabases (10GB) covering the whole country, and it’s located locally on the C-drive of the FME Flow server. Users specify a bounding box to extract the data for their area of interest.
To make the current setup faster, I have played with indexes and made sure that I’m doing a bounding box intersect on the FeatureReader, etc. But it still takes at least 10-15 minutes to get the output.
One other idea that I’m playing with is to use a different format for the source data instead of geodatabase. GeoPackage got a mention somewhere; FlatGeoBuf apparently is fast; and I have heard good stories about GeoParquet. Any other formats I should consider?
Has anyone done any comparison on this? Any pitfalls / drawbacks I should be aware of?
At the moment I’m looking more at file-based formats, as formats that require additional (database) software would involve IT too much.
I will do testing myself as well, and post some findings here later.

What are fast Geospatial Formats to Read?

 +16
+16- Enthusiast
Best answer by bwn
IMO, you want speed, efficiency and flexibility from a file based storage: Use Spatialite
Spatialite:
- Natively compresses data and automatically varies field width storage space, no matter what the Table Field width definition is. It will consistently be disk space effieicnt, and in testing has been nearly as good a Parquet with max compression setting.
- It uses SQL in the backend to read the data. There are LOTs of ways to parameterise the queries to it. Way more than ESRI has provided with their FGDB interface. Can even use it in SQLExecutor as opposed to a Reader.
- It can natively be used within QGIS, ArcGIS (although ArcMap before 10.6 does not use the Spatial Index properly when layer rendering…..haven’t tried in Eg. ArcGIS Pro)
- Is portable. All data in one file.
SQL Functions can use/be parameterised within SQLExecutor
https://www.gaia-gis.it/gaia-sins/spatialite-sql-5.1.0.html
Surprisingly also, it appears from testing, Safe has enabled searching the spatial index in Spatialite…..this is not a straightforward query to build, and if you want to do this manually in a SQLExecutor then see Alessandros’ guide (Spatialite’s lead developer) here in using the Virtual Spatial Index inside a SQL statement:
https://www.gaia-gis.it/fossil/libspatialite/wiki?name=SpatialIndex
Below I’ve set up a monster Cadastral dataset, with a 9,600,000 polygon feature table with 38 fields all populated with data and written into both a Spatialite test file and a test FGDB to compare.
Given a FeatureReader a 1 km x 1 km box to search for Intersecting Polygons
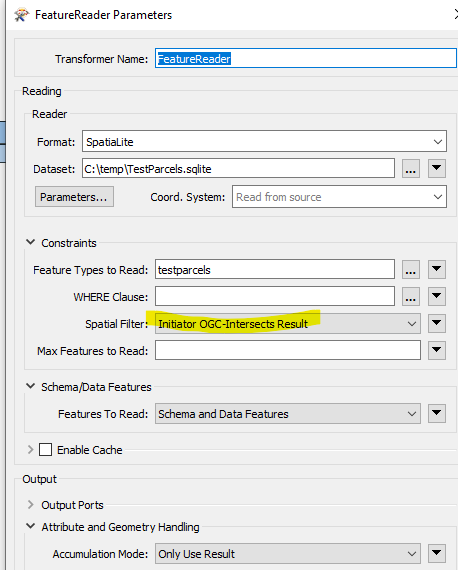
This returns 27,500 intersecting polygons from the search of the 9,600,000 features.
- Spatialite FeatureReader = 2 seconds (!)
- FileGeoDB Open API FeatureReader = 403 seconds (to be honest, it appears the API didn’t use any spatial index at all)
- FileGeoDB Proprietary (ie. Need ArcGIS installed/licenced on FME system) = 5 seconds
Expanding to a 10 km x 10 km box get 77,200 intersecting features
- Spatialite FeatureReader = 4 seconds
- FileGeoDB Open API FeatureReader = 455 seconds (Confirms API through FeatureReader does not appear to use any spatial index)
- FileGeoDB Proprietary FeatureReader (ie. Need ArcGIS installed/licenced on FME system) = 7 seconds
Other formats more in progress to watch for the future will be DuckDB (haven’t tested if FME have enabled spatial index search), which may eventually pass Spatialite’s capabilities...it doesn’t quite yet have as flexible spatial API. GeoParquet from what can see developers have not yet decided if/when to implement a Spatial Index and how to include that in the standard for writing and accessing and would suspect be behind Spatialite and DuckDB for the near-future.
Beyond just its spatial capabilities below, it has proven to be hugely scalable and performant from its SQLite base. I have separately built a 1 TB SQLite database time series event logger with 100s of millions of timestamped events in it. If indexed properly in the way SQLite optimises its query searches (ie. Build proper Multi-field indices and give hints to the query on how to use it), it finds and returns rows within the date/time WHERE clauses within seconds. Although it does take quite a bit of experimentation/learning how SQLite works to get to this scale of query performance.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.














Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.