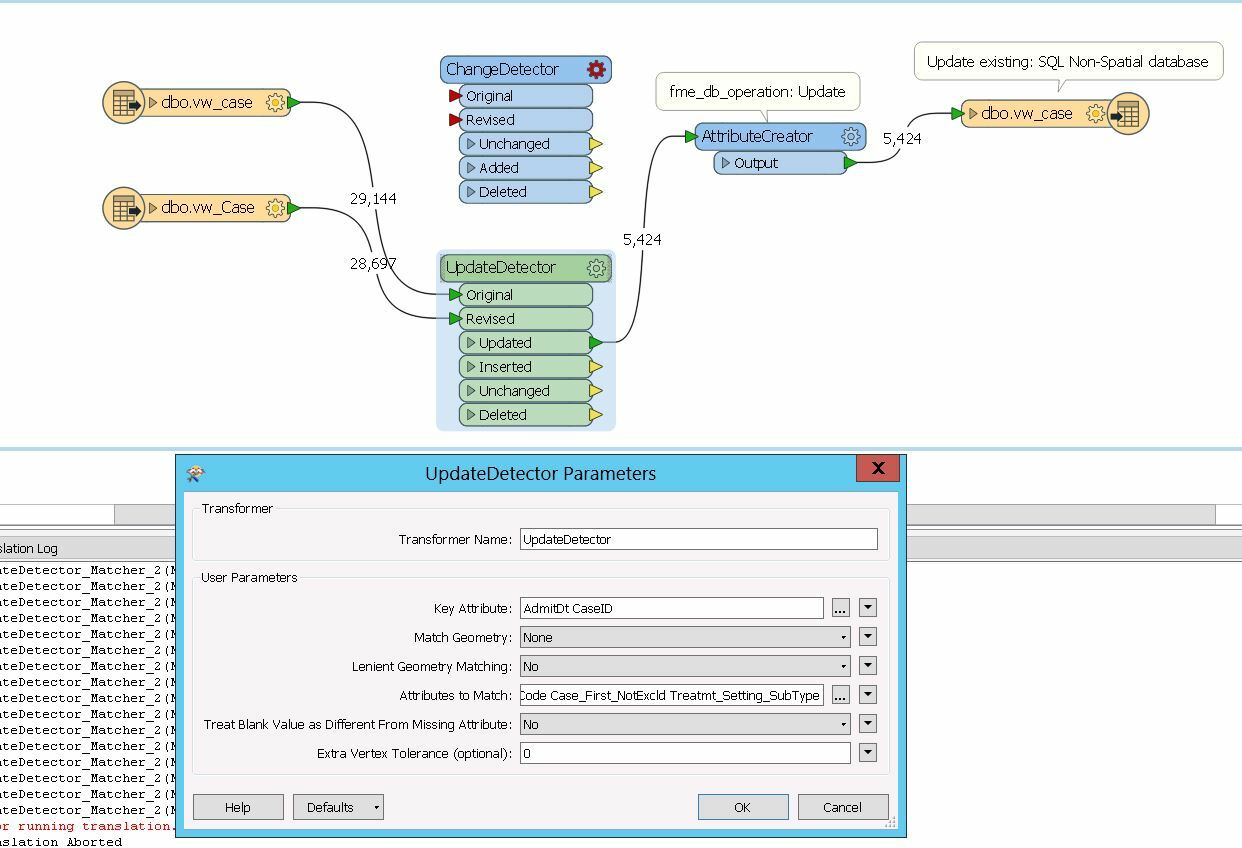
The following workflow of comparing tables (in two separate databases) and updating an existing database (SQL non-spatial) is taking for ever. It has been running for 12 hours now to update the database. In 12 hours only 5424 records are compared. I am expecting about 20,000 records to be updated weekly based on update detector comparison. The change detector transformer is in the workbench since I tried that approach as well but failed. How can I make the workflow run faster?