Hi,
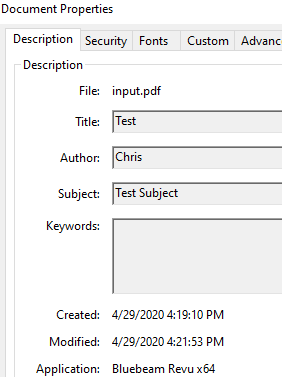
We are daily updating a number of PDF's with FME for publication on our website but these files need to have the Document Properties set. Our webcare team won't allow for the pdf's to be published. So far I'm not able to achieve this.
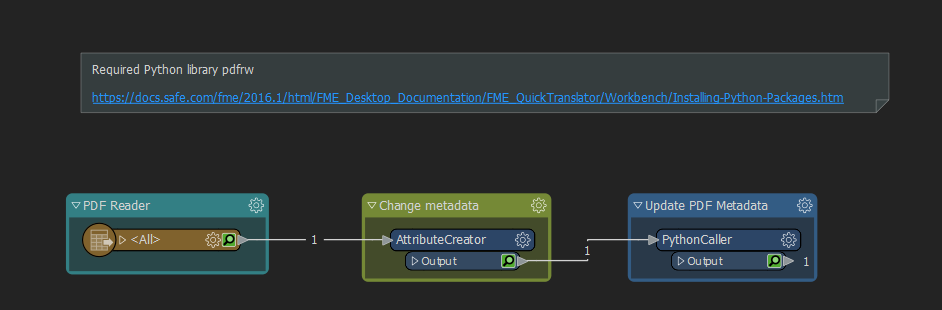
There seems to be an option with the format attribute 'pdf_document_info_metadata' but how do I format the properties in my writer?
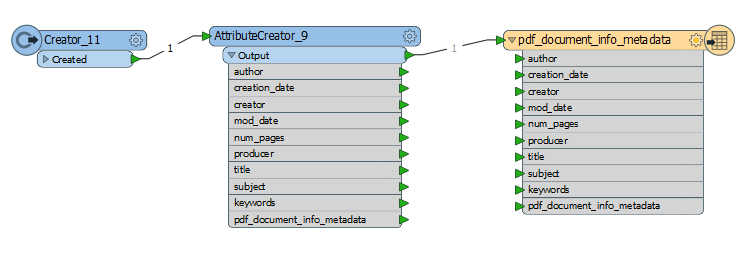
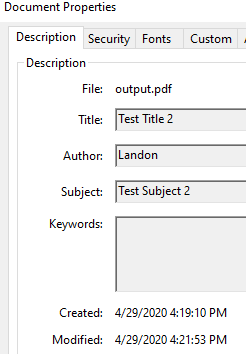
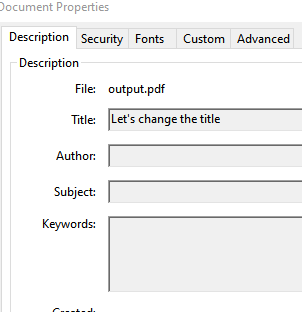
When reading a pdf which has these properties filled in, pdf_document_info_metadata is a feature type. I have tried adding this feature type to my pdf writer with the exact same schema. But no result; empty properties still.
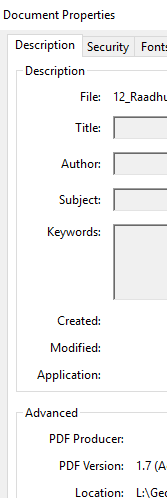 Does anyone know if writing the properties is supported and how to achieve it?
Does anyone know if writing the properties is supported and how to achieve it?