Hi all,
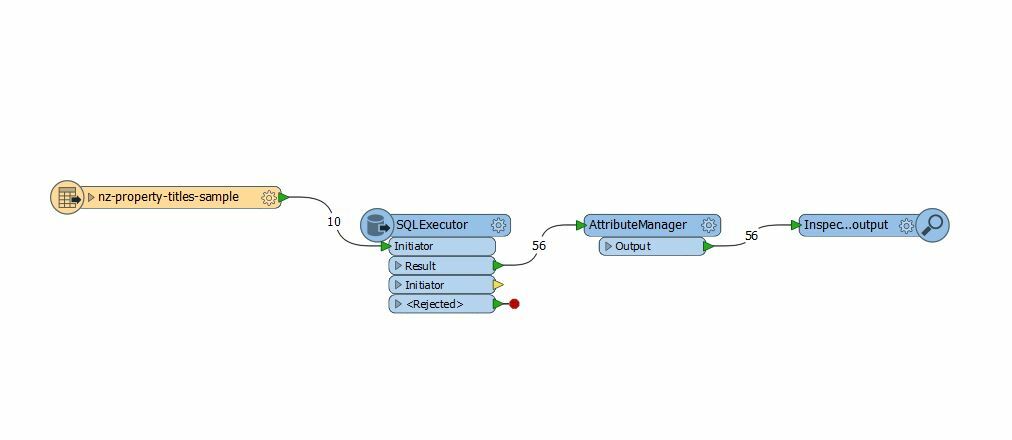
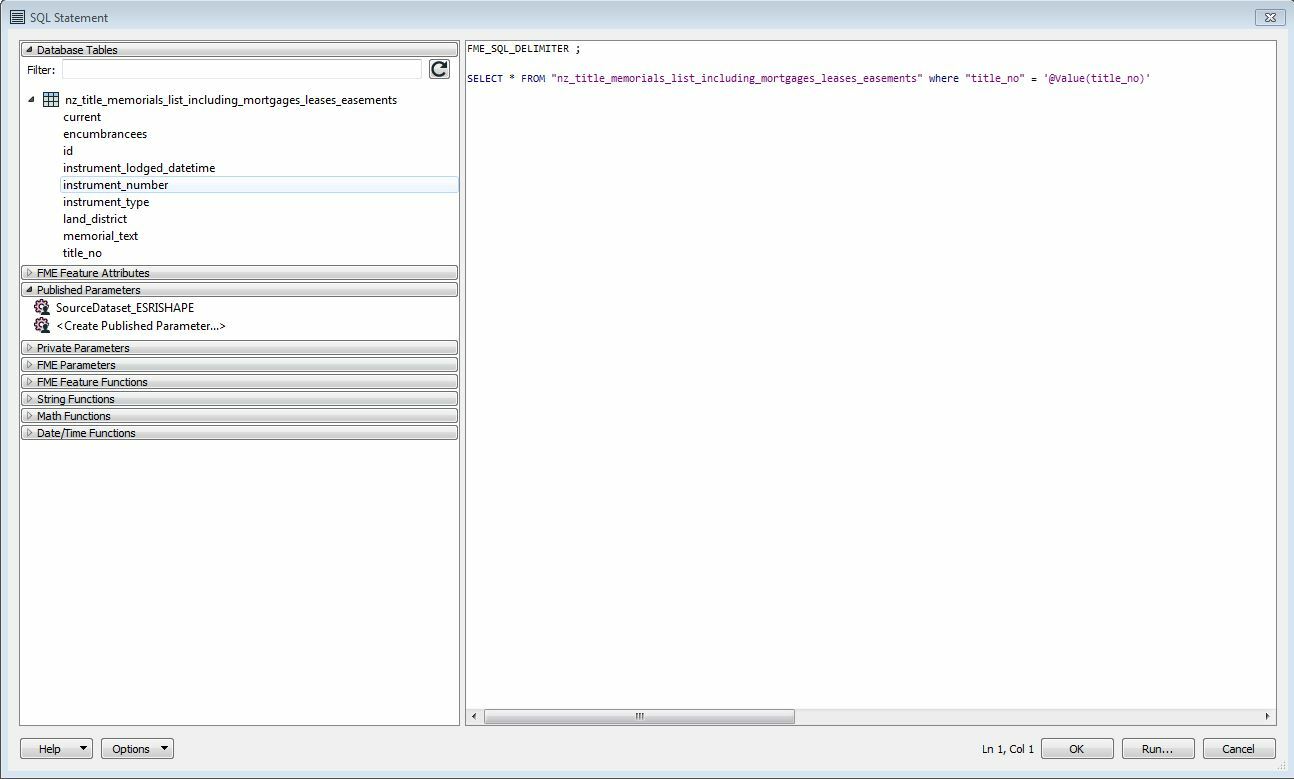
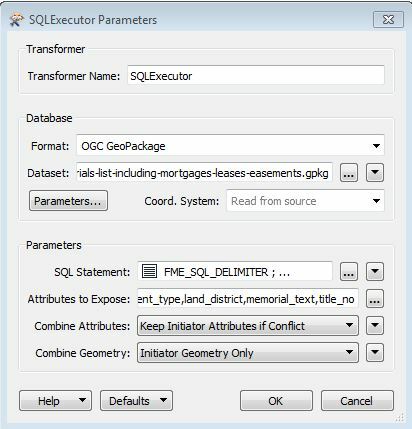
Would anyone be able to suggest a workflow of exporting non-spatial records from wfs service to csv format? It is a big file with property title information (2+ million records), so I was thinking about narrowing the search by specifying Land District (GetFeature?). I did not work much with wfs services so simplified explanation would be great.
Maybe someone from New Zealand with data.linz experience, especially their wfs services?
Regards,
Maksym




")