


Hi,
I am trying to insert a watermark disclaimer into construction PDF's as part of a distribution workspace that is an part of a FME Server App.
The key part of the workspace is that pdf's are filecopied into a zipped folder before being distributed, these pdf's range in size (napkin to Arch D, to legal letter, whatever was scanned), but the disclaimer can be in the same spot (ie. bottom left hand corner, 150x, 150y).
The PDF writers limitation is that it can only write to certain page sizes, which is an issue, so inserting a text disclaimer is not feasible.
The filecopy maintains the page size/pdf quality, but I am at a loss for adding a watermark/overlay/text.
FME Desktop 2021.0
FME Server FME Server 2021.0.1
Thanks!





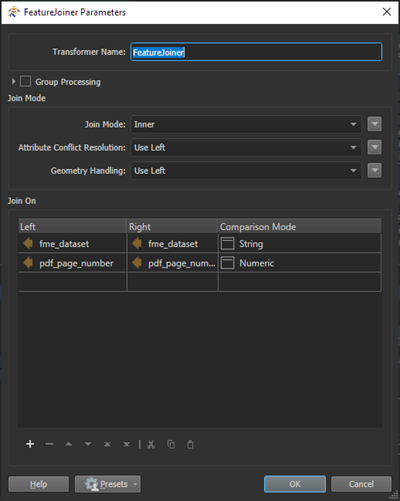 For the FeatureJoiner in the Python workflow (bottom bookmark):
For the FeatureJoiner in the Python workflow (bottom bookmark):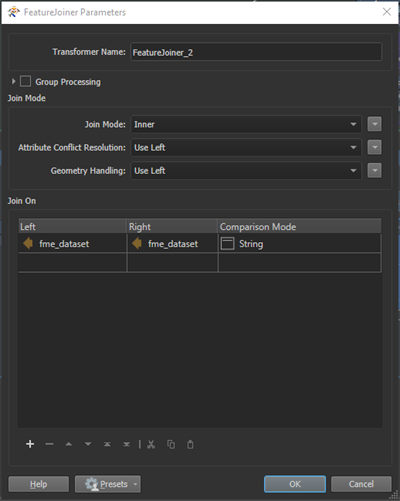 I've also included a 2021.0 version of the workspace in case it helps.
I've also included a 2021.0 version of the workspace in case it helps.