I've been given a CSV file that has a mixture of line ending types, some are LF and some are CR.
The first line is blank with a LF, followed by a header line with a CR then all the data records which are terminated with LF's. The CSV reader is thinking the terminator is LF so thinks the header line is both lines 2 and 3 which is messing it up.
Other than reading the file in as a whole and changing the CR to LF, saving it and reading it in again does anyone know how to read this in?
Best answer by tomf
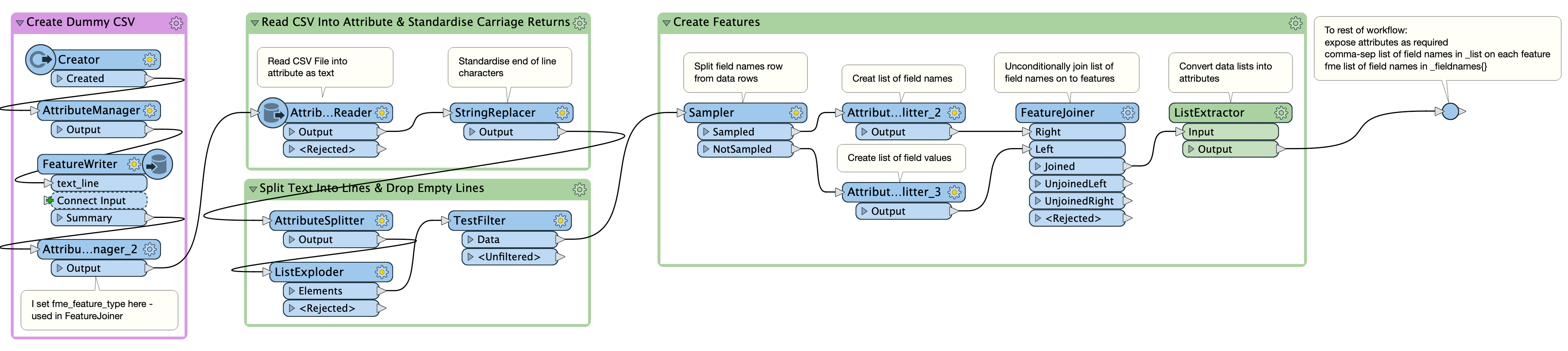
This would be my approach without resaving a corrected file (Quick solution). It still involves correcting/standardising the line end characters, but that's probably necessary. Here I've faked a CSV with a mix of line ending characters based on your description, then written out. Testing that file with a standard CSV reader produced a similar effect to yours.
The output of this does produce unexposed attributes, but if you have a fixed schema it would be trivial to set up an AttributeExposer to expose all the attrbutes to the rest of the workflow. Has attached the below workspace (FME 2020.2)
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
This would be my approach without resaving a corrected file (Quick solution). It still involves correcting/standardising the line end characters, but that's probably necessary. Here I've faked a CSV with a mix of line ending characters based on your description, then written out. Testing that file with a standard CSV reader produced a similar effect to yours.
The output of this does produce unexposed attributes, but if you have a fixed schema it would be trivial to set up an AttributeExposer to expose all the attrbutes to the rest of the workflow. Has attached the below workspace (FME 2020.2)
This would be my approach without resaving a corrected file (Quick solution). It still involves correcting/standardising the line end characters, but that's probably necessary. Here I've faked a CSV with a mix of line ending characters based on your description, then written out. Testing that file with a standard CSV reader produced a similar effect to yours.
The output of this does produce unexposed attributes, but if you have a fixed schema it would be trivial to set up an AttributeExposer to expose all the attrbutes to the rest of the workflow. Has attached the below workspace (FME 2020.2)
Thanks Tom, that's perfect and saves writing to the temporary file. I just need to test if it works as efficiently as the temp file method with upwards of 1 million lines in the csv.