
I have address data in CSV format. there are address number ranges, street address from number and street address to number, and sequence code (1 for odd, 2 for even, and 3 for consecutive).
I need to expand these ranges into individual addresses based on sequence code and write them in a new CSV.
Any guidance for doing this task in FME would be appreciated. Thanks

Solved
Expand address ranges in FME

 +7
+7- Contributor
Best answer by ev_robin
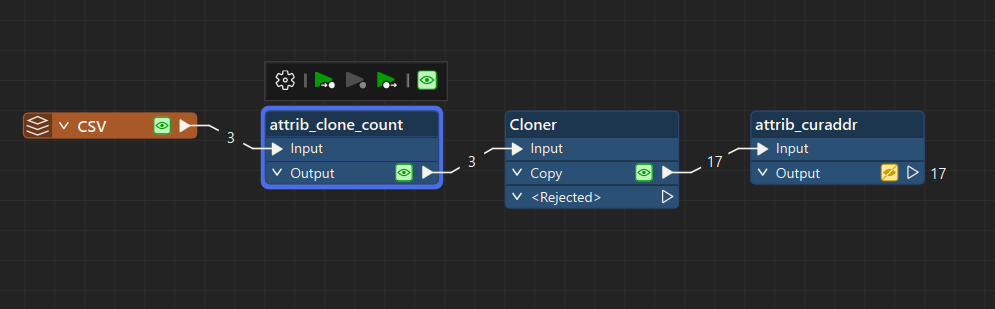
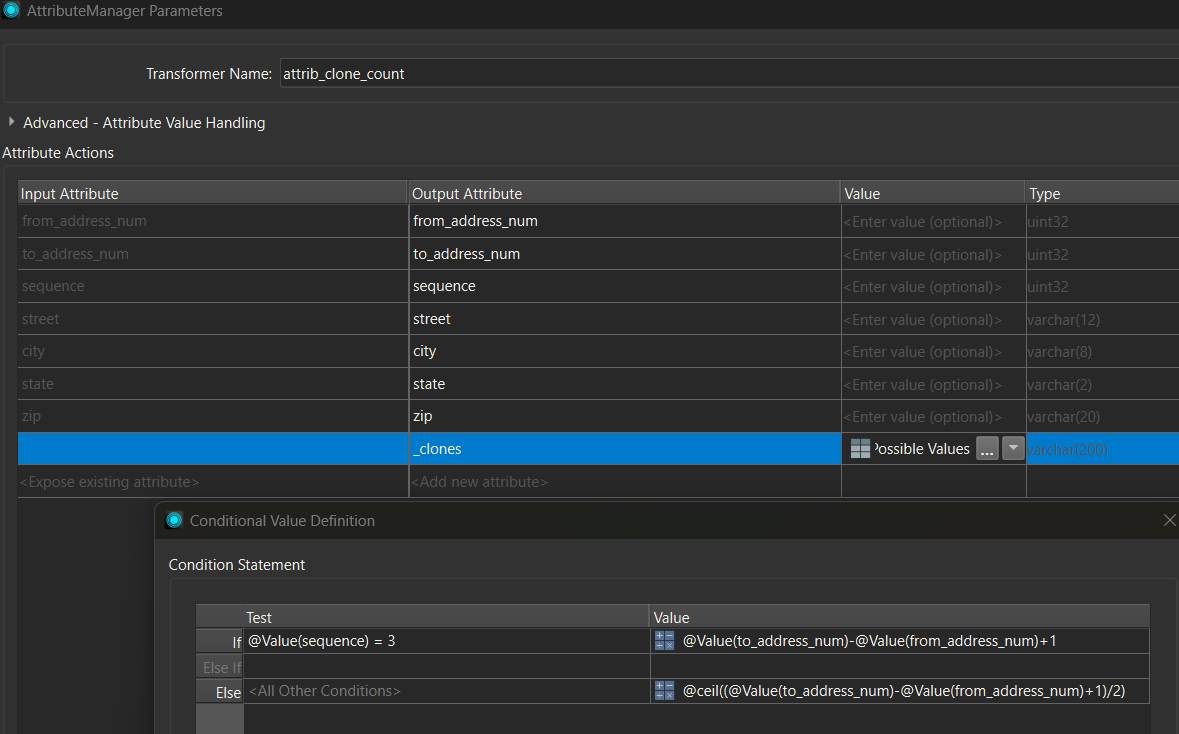
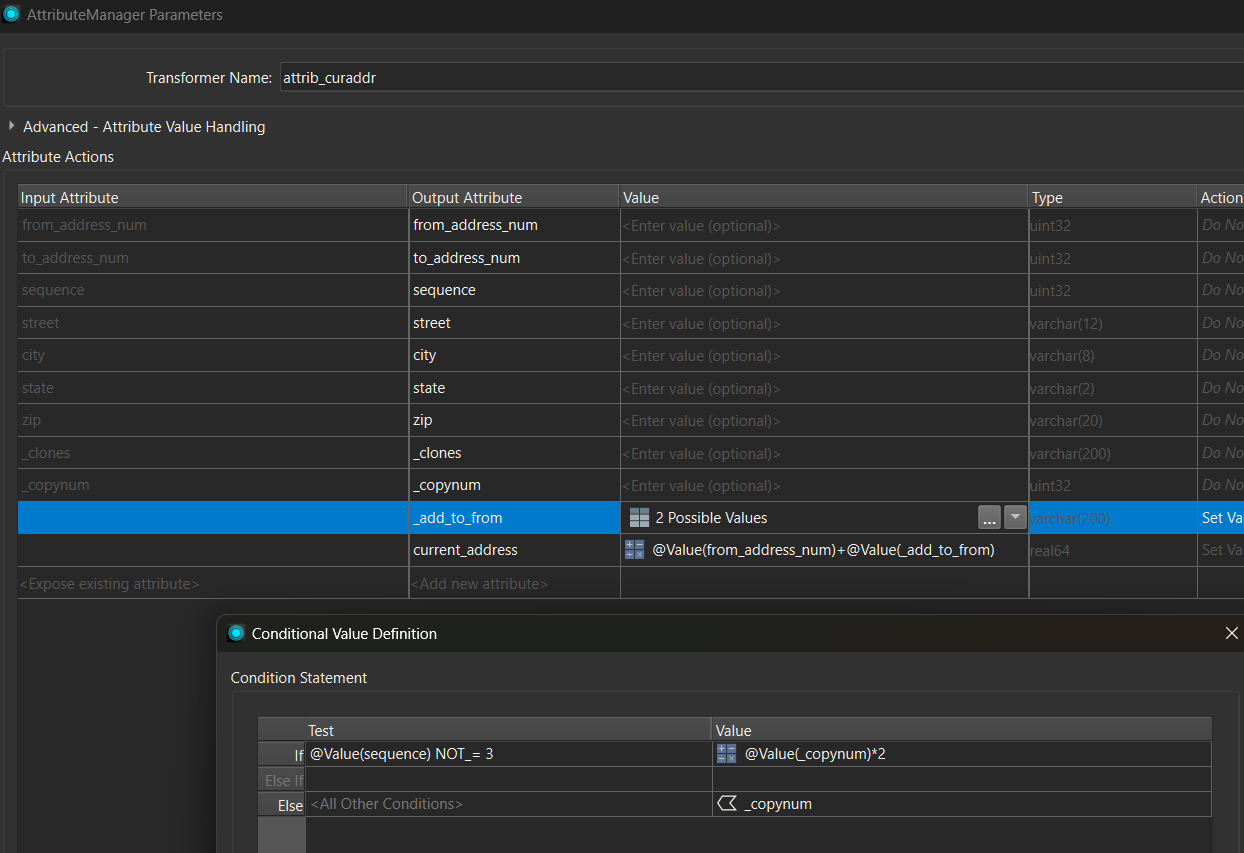
If I understand your question correctly, you would like to create a CSV entry for every address in the range specified by each row. A cloner might be a simple way to do that. Some attribute managers can handle populating the fields. I’ve attached a workspace that might help as a sample.
Start:
from_address_num to_address_num sequence street city state zip
1 9 1 baker st. new york ny 00000
2 6 2 baker st. new york ny 00000
101 109 3 broadway st. new york ny 00000
End:
current_address from_address_num to_address_num sequence street city state zip
1 1 9 1 baker st. new york ny 00000
3 1 9 1 baker st. new york ny 00000
5 1 9 1 baker st. new york ny 00000
7 1 9 1 baker st. new york ny 00000
9 1 9 1 baker st. new york ny 00000
2 2 6 2 baker st. new york ny 00000
4 2 6 2 baker st. new york ny 00000
6 2 6 2 baker st. new york ny 00000
101 101 109 3 broadway st. new york ny 00000
102 101 109 3 broadway st. new york ny 00000
103 101 109 3 broadway st. new york ny 00000
104 101 109 3 broadway st. new york ny 00000
105 101 109 3 broadway st. new york ny 00000
106 101 109 3 broadway st. new york ny 00000
107 101 109 3 broadway st. new york ny 00000
108 101 109 3 broadway st. new york ny 00000
109 101 109 3 broadway st. new york ny 00000
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
")
Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.