Hi all,
I am trying to create a workbench that will read/download 52 individual URLs and write them as 52 individual feature classes in a file geodatabase as well as 52 individual dwgs both using part of the original URL as the file name and for the file geodatabase as an attribute under the feature class. I will hopefully have this run monthly as a batch file.
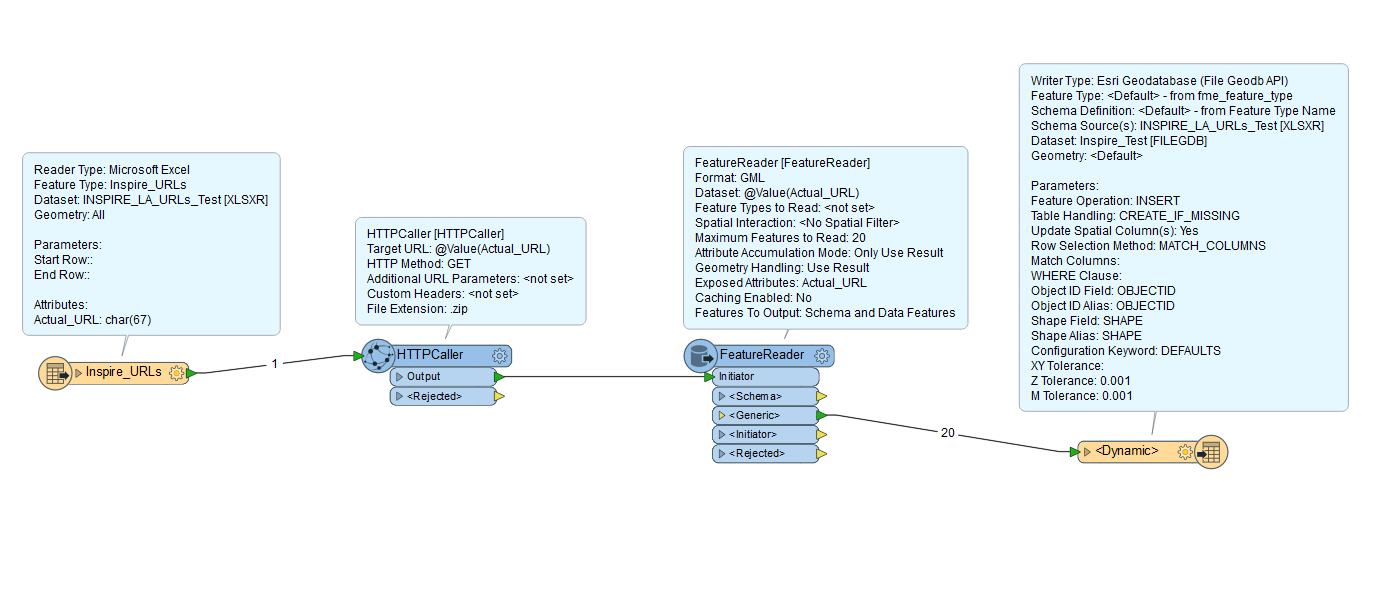
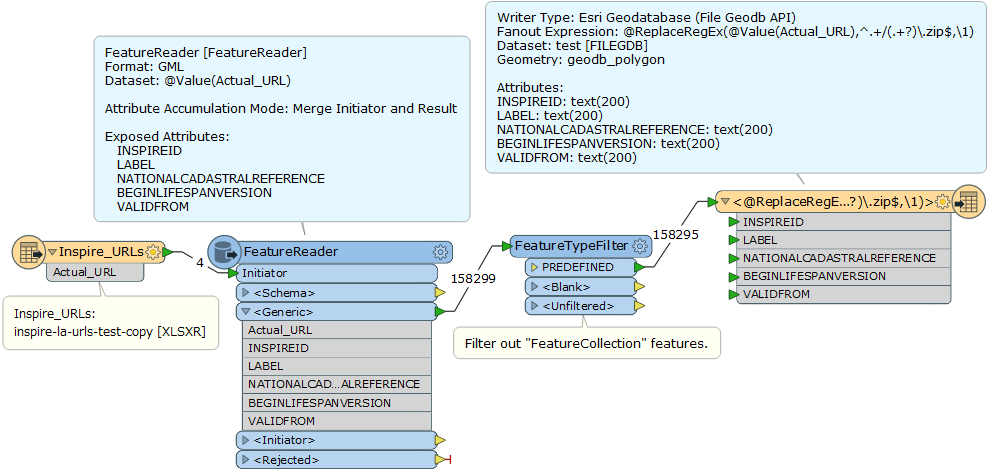
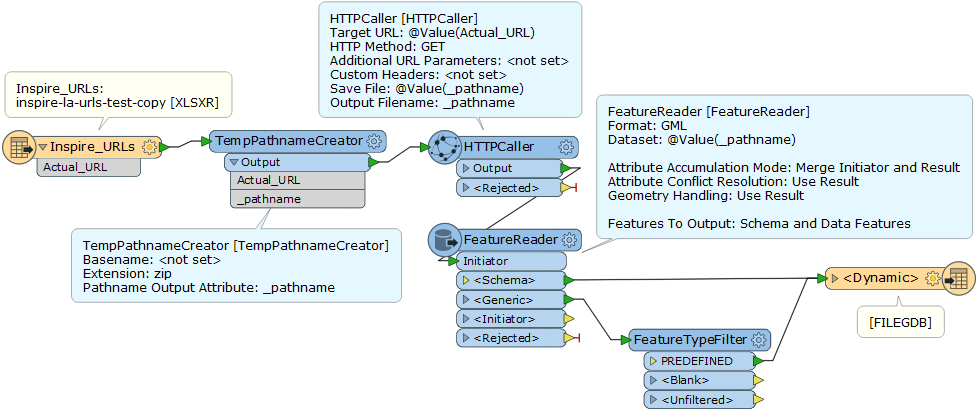
I have a list of 52 URLs that are stored in a spreadsheet (example of a few attached). Each URL is a download link for a .zip file that contains an individual GML file. I can pass the URLs successfully to my HTTPCaller which saves the response body to file.
An example of the original URL called is this below:
http://data.inspire.landregistry.gov.uk/Kensington_and_Chelsea.zip
Whereas the response file that is saved is called
'http_download_1497369123968_8888.zip'
I need to have a way to transfer the actual URL name from the spreadsheet so that it can be an attribute of my output. I'm not sure how to do this?
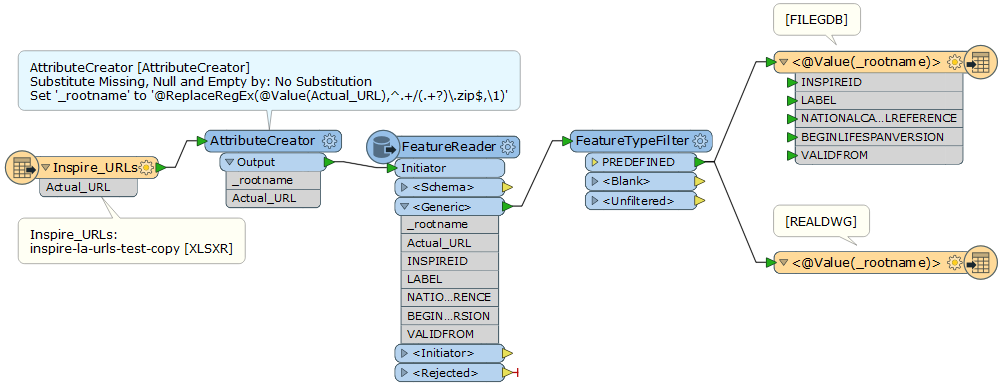
Below is a screenshot of my workbench as it is currently, when I try to run it the three problems I get are:
- An error stating “FileGDB Writer: A feature with feature type `PREDEFINED' could not be written”.
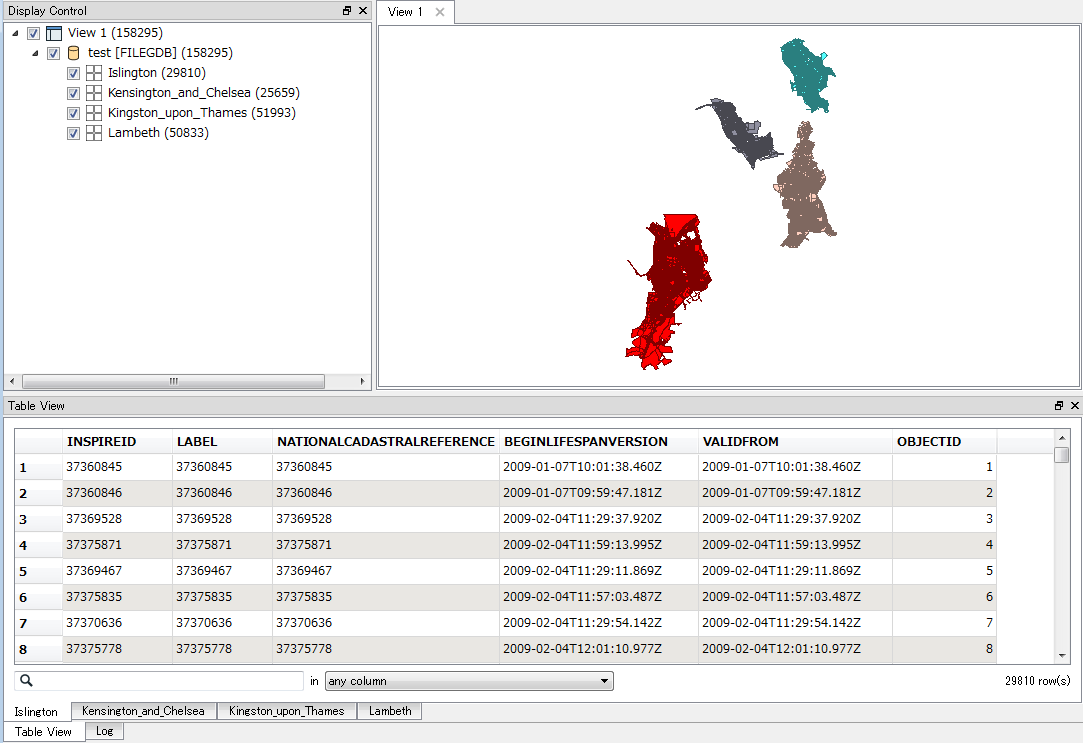
- I don’t know how to relate the response file path to the URL name so that I know what local authority each refers.
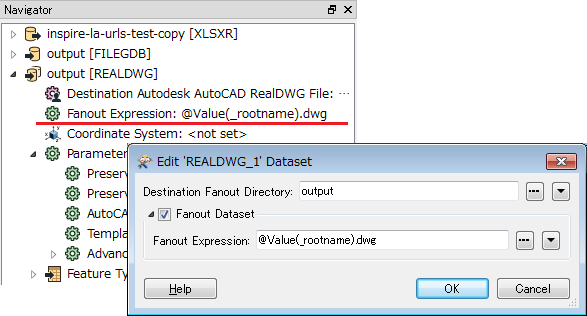
- I don’t know how to write each as an individual feature class. I haven’t even looked at the dwg part yet.
Any help anybody can give me would be greatly appreciated, thanks.