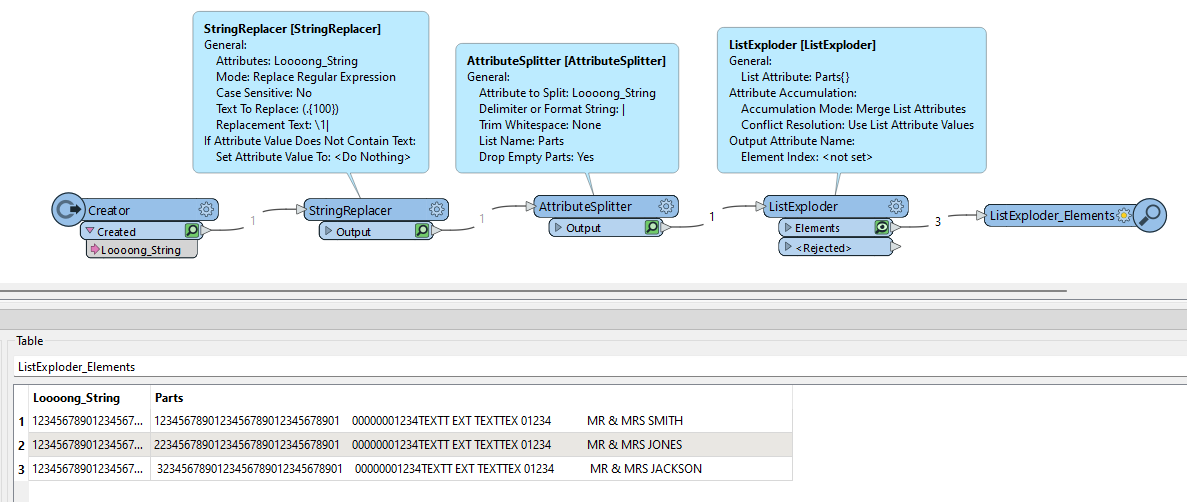
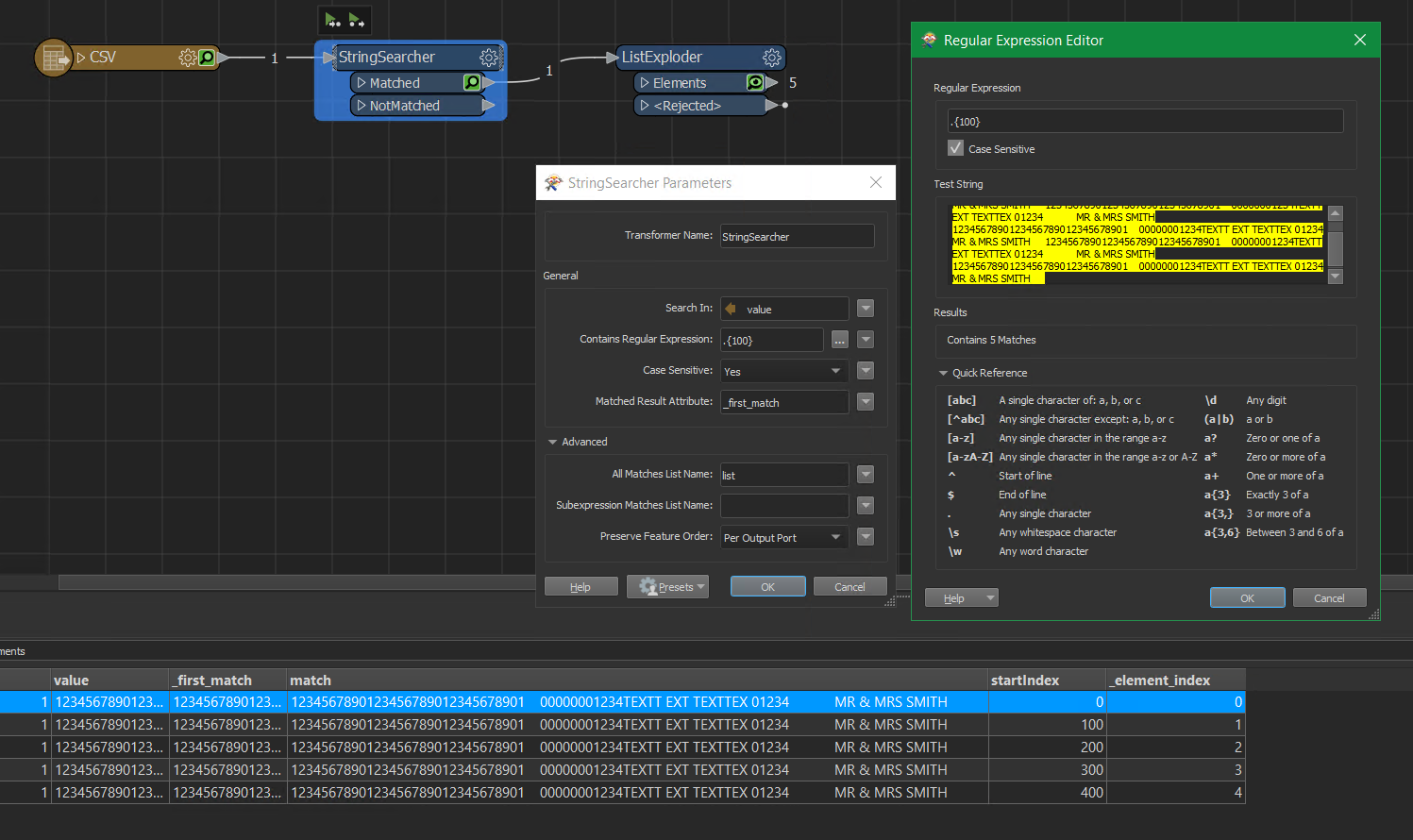
Hi
I have a long line of text_line_data that contains payment details.
I want to save the data to a data or text file but have the body of the data split at every 100 characters and then print the next payment detail so that each persons output is on a new line until there are no more details.
I have used string padders to get each attribute and testers to create an attribute containing payment details from 1-100, 100-200, 200-300 etc. which does work but is not dynamic. Is there an easier way to split text every 100 characters to a new line? Any help/hints would be appreciated.
Basically, I’d like to output the following long attribute text_line_data…….
1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH 1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH 1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH 1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH 1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH 1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH
to separate lines 100 characters long, like this…...
1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH
1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH
1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH
1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH
1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH
1234567890123456789012345678901 00000001234TEXTT EXT TEXTTEX 01234 MR & MRS SMITH