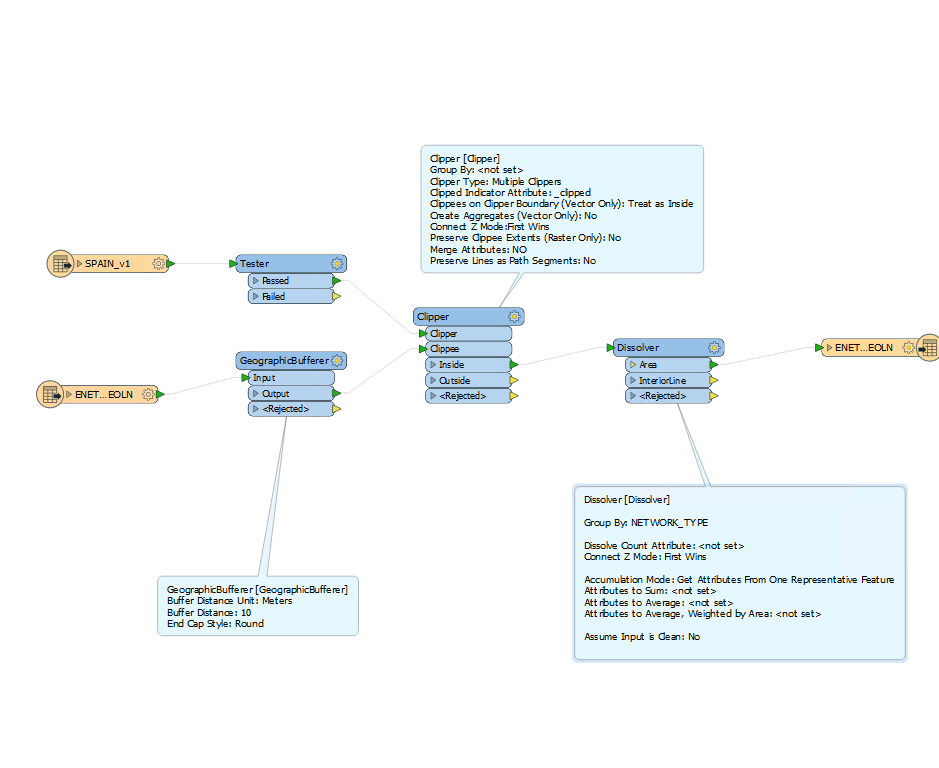
I'm new to FME. I have a process that intersects a line buffer from Oracle with a shp stored in local. In the end there is a dissolver to reduce the number of polygons and write it in a shp.
The problem is that from Oracle come 11 million records ... and in the dissolver I get an error.
My question would be if there would be a way to execute the process in the following way: that I read 500,000 records, process them, write them in the shp, then another 500,000, then others and so on until the end. It could be done?