Hi everyone,
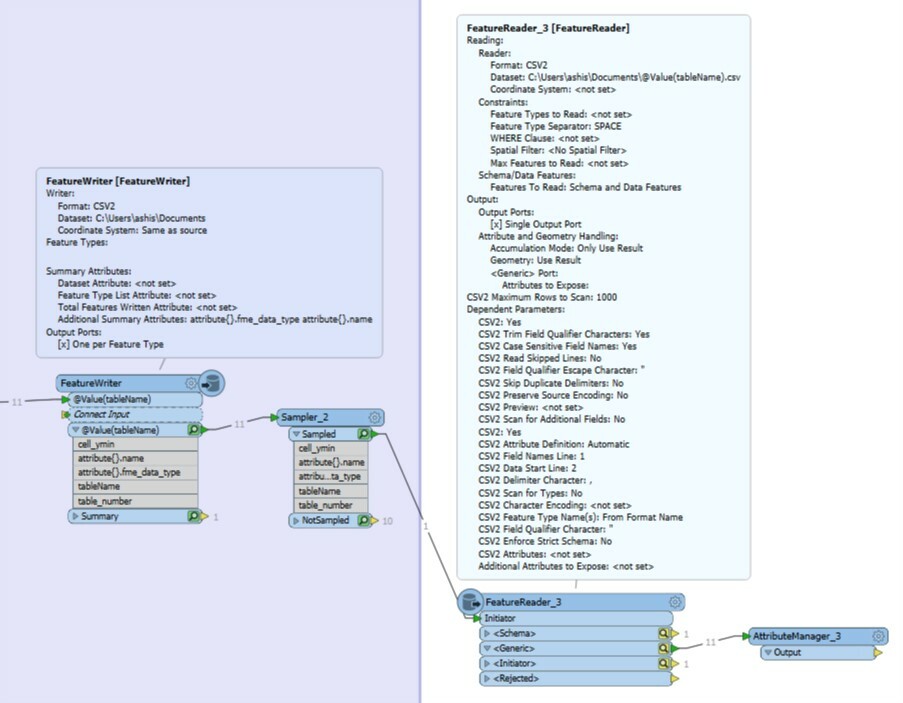
I have a workflow in which I have to change the schema dynamically. I was able to write the result I want into a CSV file by using a FeatureWriter (or a CSV writer) and setting Dynamic Schema Definition with Schema sources as "Schema From Schema Feature". The features passed in have list attributes name and fme_data_type.
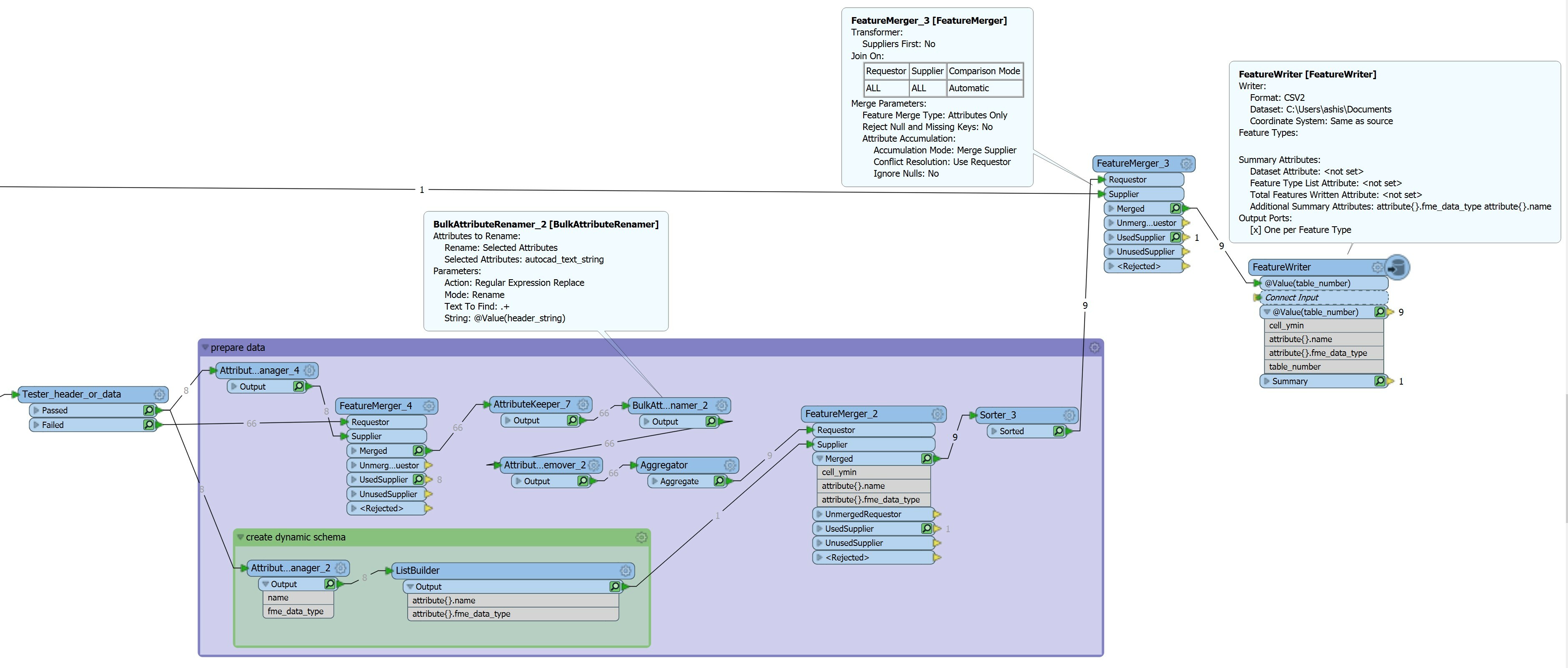
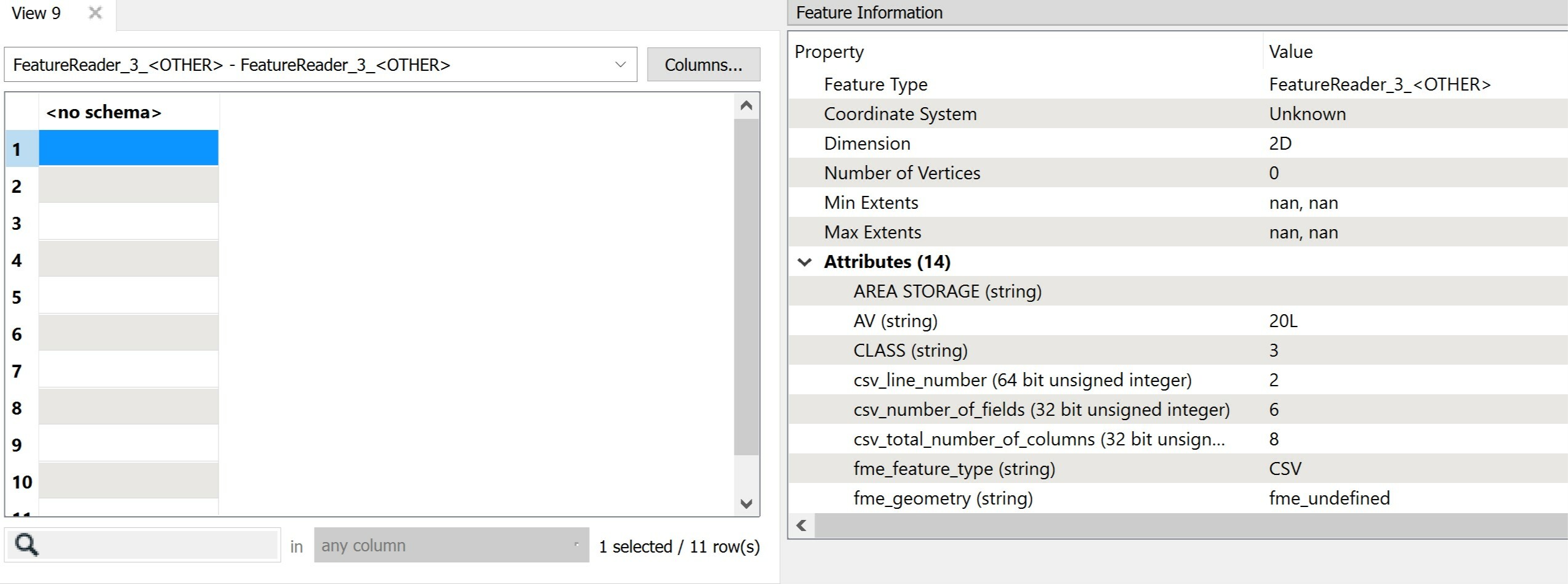
The table in the output CSV file is correctly formatted into the new schema. However, the data from the output port of FeatureWriter is in the same schema format as the input to it, (not in schema format written in CSV). I want to change schema in FME so that I can process it further. Is there some setting in FeatureWriter that Im missing? or any Alternative workflow to change the schema ?
Thanks in advance,
Ashish