Hi, I could probably work this out over days (weeks!) but I figured asking the question here may be a quicker method to the end goal!
As a first line, I am working in FME(R) 2018.1.0.0 (20180717 - Build 18520 - WIN32) which is unchangeable due to it being what is installed/available at my place of work. Just in case this affects a solution.
Also, this is my first time posting here, so apologies if this is vague/long winded/wrong format etc.
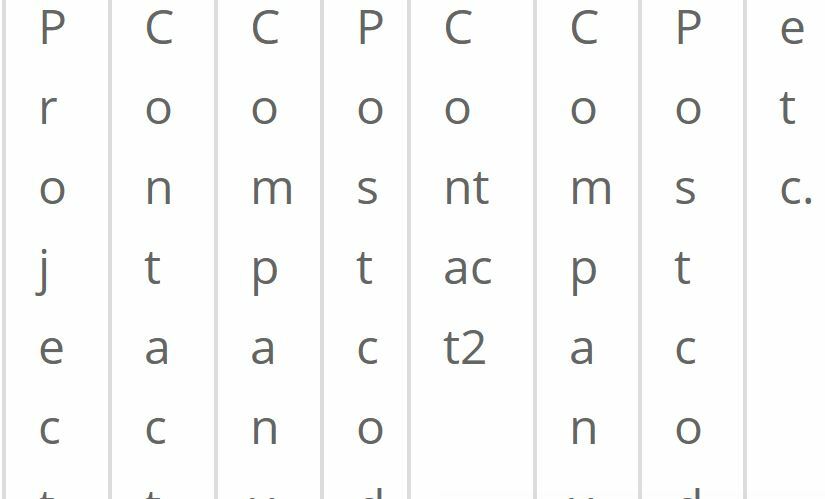
I have a spreadsheet with each row being a project and multiple columns showing the names and addresses of people involved in the project. I have successfully run this through FME to amend the various raw details into the format required to distribute as I require.
However, I now need to generate a duplicate free list of all the 'contact name'/'company name'/'postcode' which I will then be able to reference back to the original format of the spreadsheet (i.e. a row per project with multiple 'contact name'/'company name'/'postcode' columns for each).
The concept of creating a duplicate free list seems simple enough, but I can't think how I would reference back to the original dataset. I'm thinking lists are the answer and have seen there are many 'List...' transformers but I don't really know where to start.
The aim is to pass a duplicate free list (with three columns: contact name/company name/postcode) to a colleague for them to reference against their systems and then to be able to highlight any matches in my original dataset (row per project and multiple columns as above).
I'm thinking I'd need some sort of unique reference number per row/column combination for each, but what about 'contacts' that appear on more than one project and in different columns? Once the list is free of duplicates, can each have more than one unique reference number?
Does this even make sense!
Cheers!