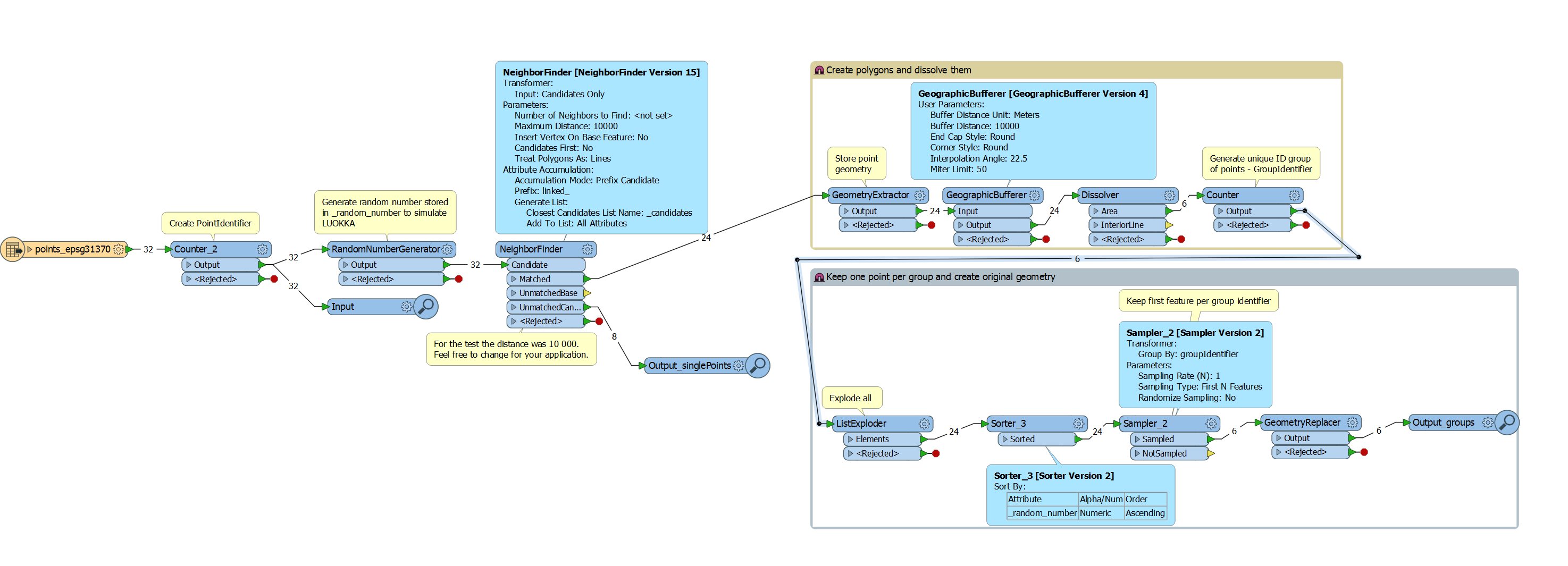
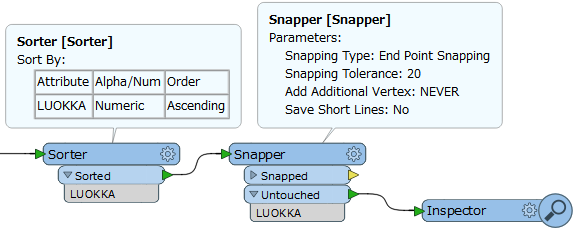
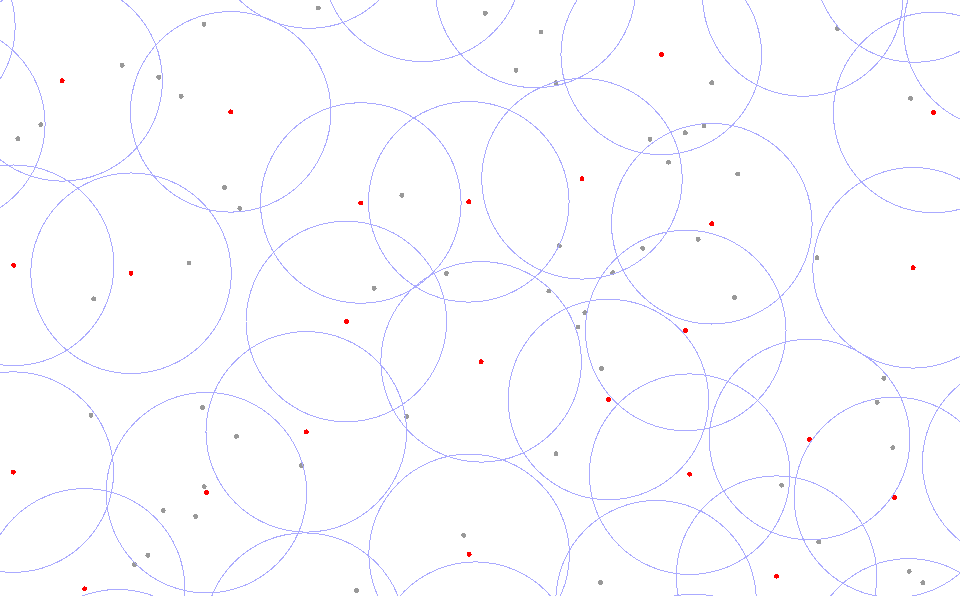
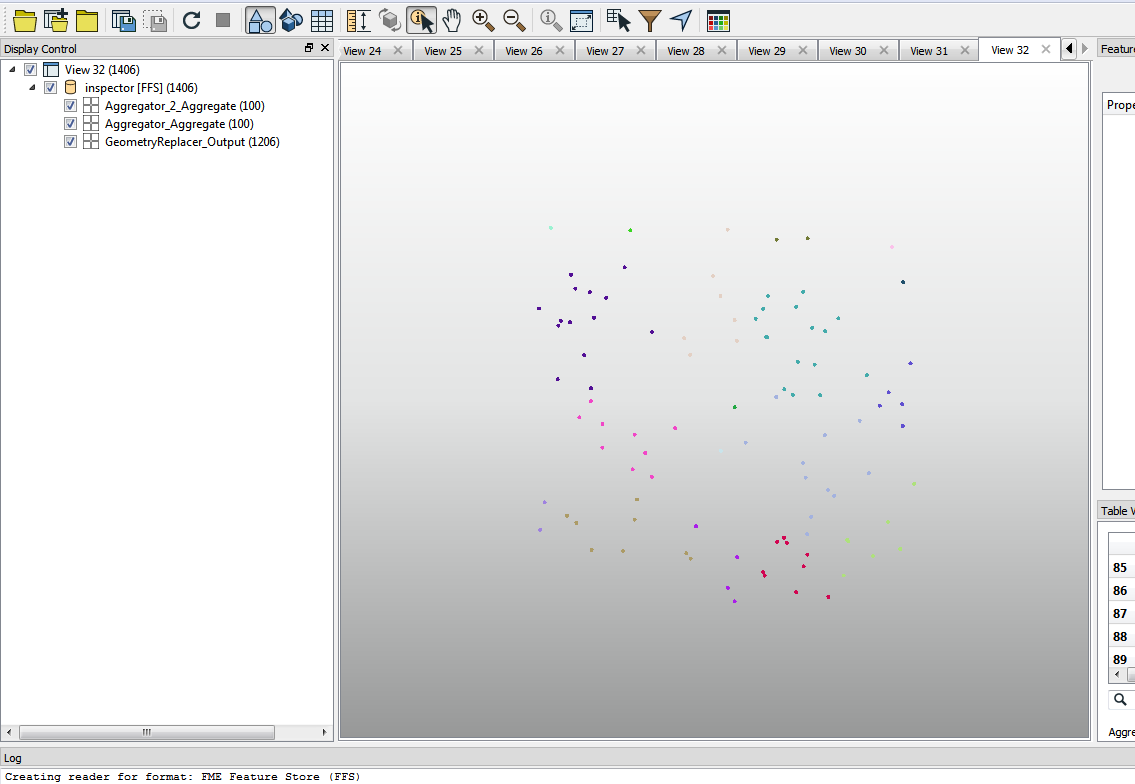
A shapefile has a lot of points in it, and many of these are too close to each other to be shown on a map.
I would like to
- identify all points which are closer than 20 meters from each other
- delete all but one of them
- and add the text "multi" into a field for each point which is left remaining but had a point too close to it