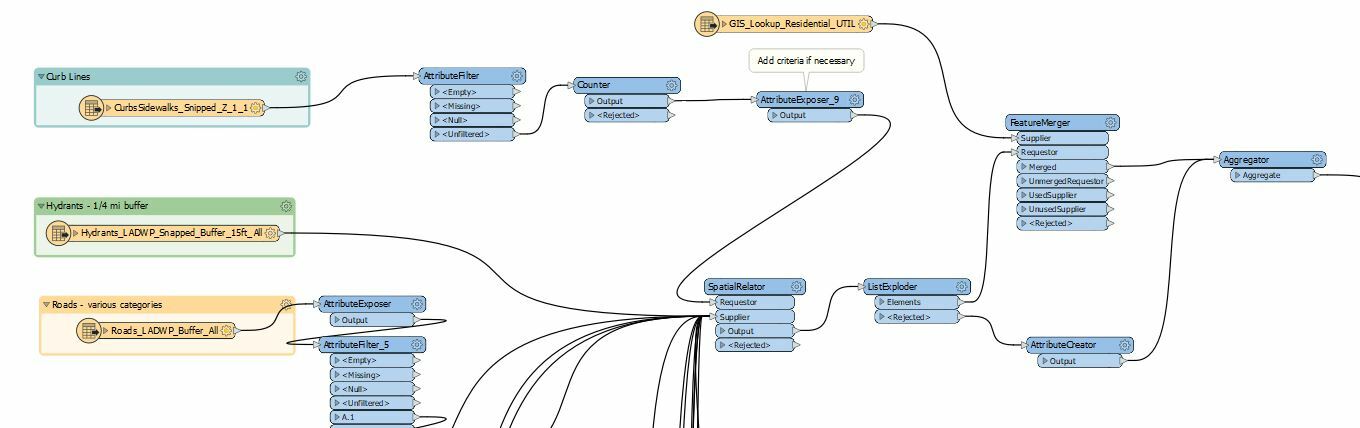
Hello!
I'm having a near meltdown trying to figure out how to rework a process that I have and hope the community can help a bit. I'm working on a project that is determined a suitability analysis on which curbs are best suited for EV installation charging. By using the SpatialRelator, I am currently processing millions of feature lines (the curbs) and comparing each line to 20-30 different datasets (polygon areas that have been prepped with preconfigured parameters) to see which of them overlap. I then use a ListExploder to explore those relationships, and then a FeatureMerger that merges the different individual "scores" for each of those 20-30 datasets. Then I run it through an Aggregator to basically generate a total "score" from each of the datasets that intersects with a particular line feature, grouped by the line feature. For a smaller dataset, it works fine!
However, trying to run 500,000 features using a WHERE clause lasted over (last I checked) 18+ hours, and then I think my computer restarted while I slept, so I have no idea how long it would have actually taken!
If anyone has any suggestions on alternatives, I'm all ears! I've attempted the FeatureReader way, but I need to maintain the intersecting relationships in order to generate "scores" for each dataset that intersects with a line. Thank you in advance for any insight.