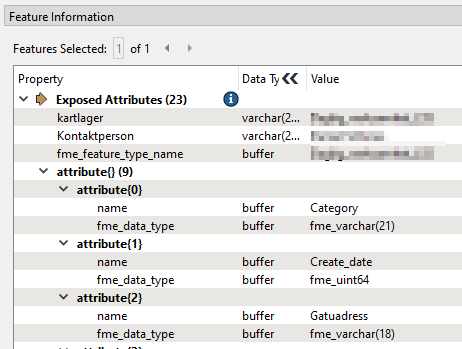
I want to loop through the list ‘attribute’ in a PythonCaller and change some values, but I get an error. Line 34 is the for-loop.
File "<string>", line 34, in input
Python Exception <TypeError>: 'NoneType' object is not iterable
Can you see the error?
def input(self, feature: fmeobjects.FMEFeature):
feat = feature.getAttribute("attribute{}.attribute")
for obj in feat:
if "fme_varchar" in obj.fme_data_type: