
I've written a workspace in the 2015 version of FME, with five readers, which all have one column headed 'REFERENCE'. The transformer 'DuplicateRemover' is producing two outputs: 'Unique' and 'Duplicate', but the inspectors reveal that both outputs contain unique values. In 'Duplicate', there are both duplicate values and unique values. Why is this, and how can I resolve this to produce only duplicate values in the 'Duplicate' output?

Solved
How does the 2015 transformer DuplicateRemover work?
Best answer by ebygomm
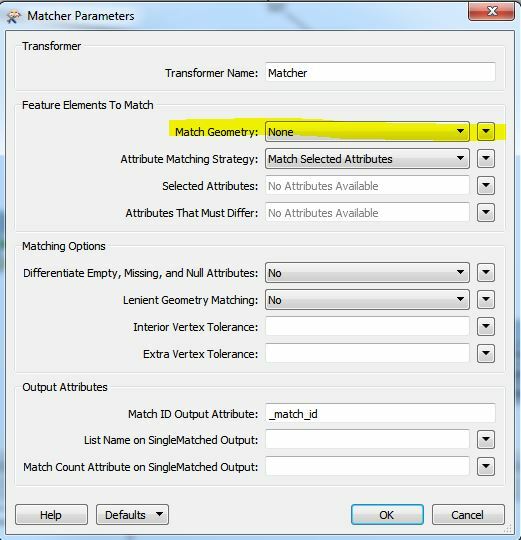
With the matcher you can choose no geometry matching
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.






