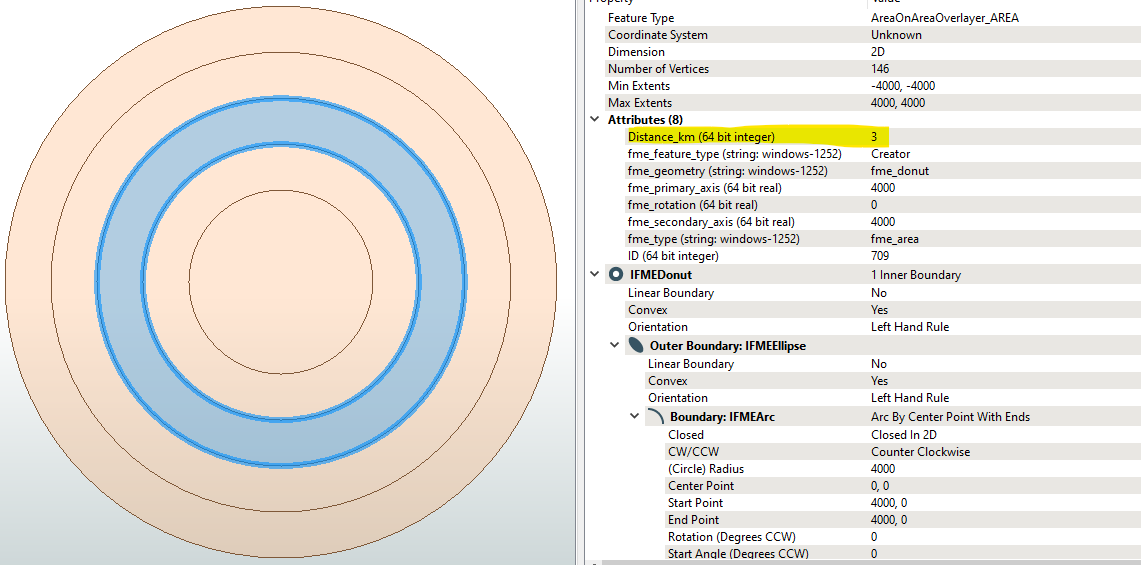
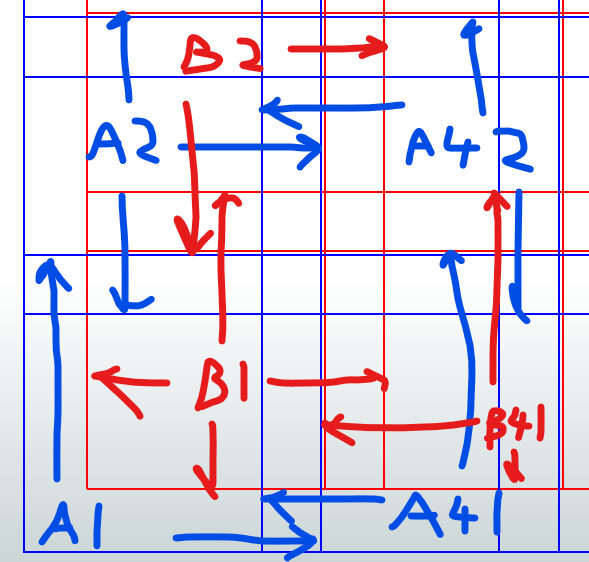
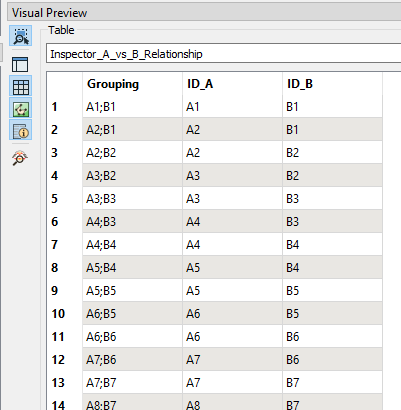
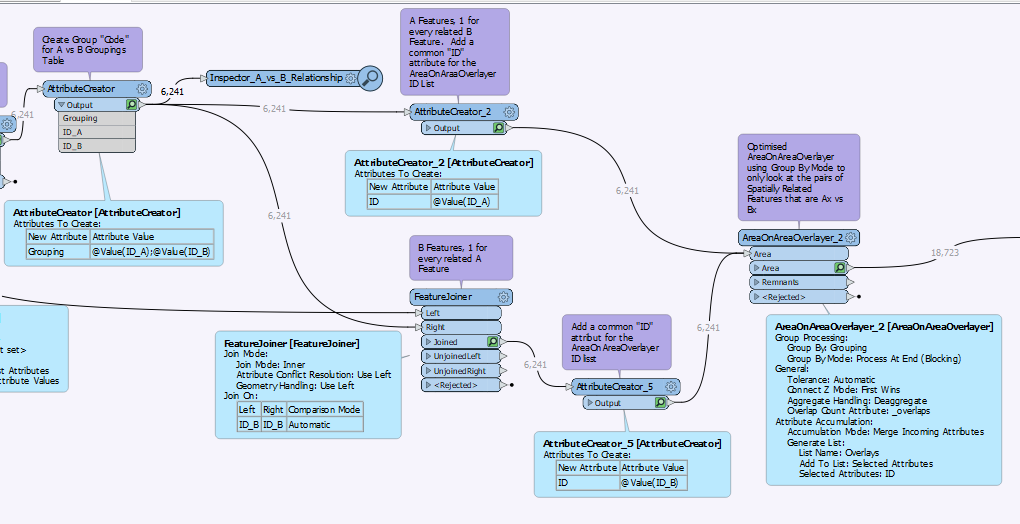
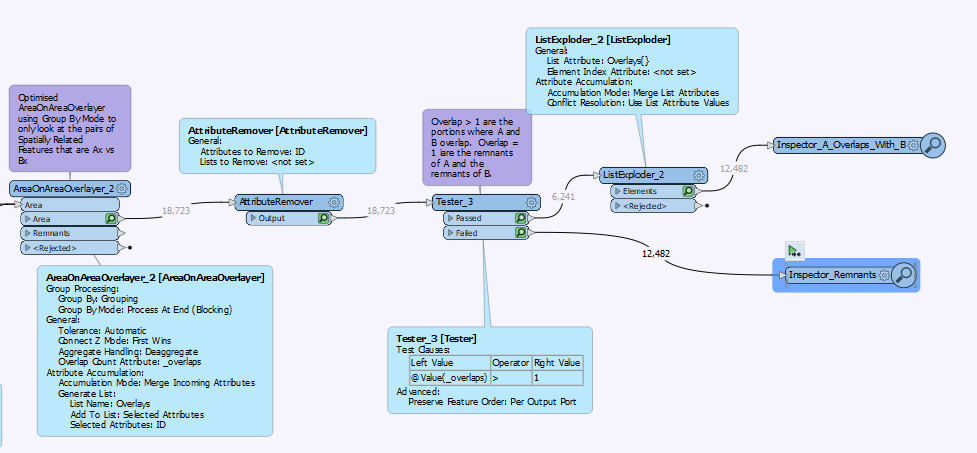
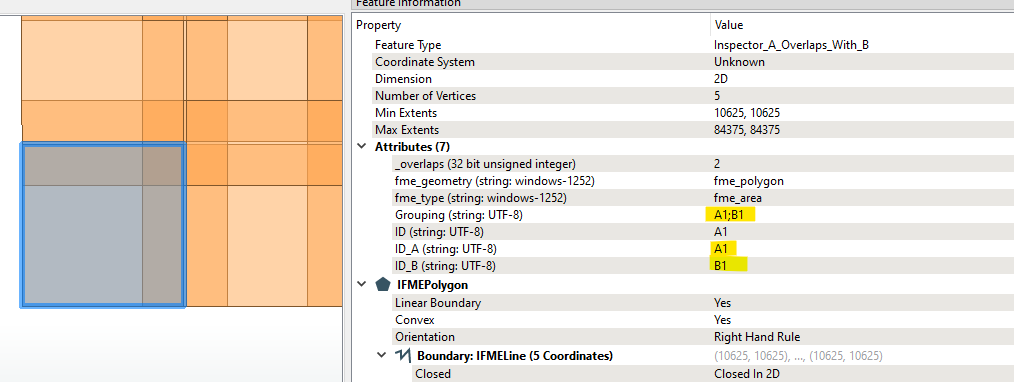
I have a table of 1600 polygons (featureset A) with most of those polygons overlapping ; they represent distance discs from a point of origin. I want to relate those polygons to another feature set (B) and calculate the %area of the intersection for each input polygon.
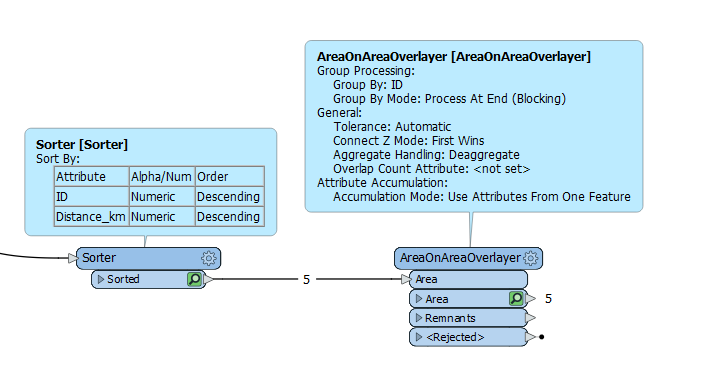
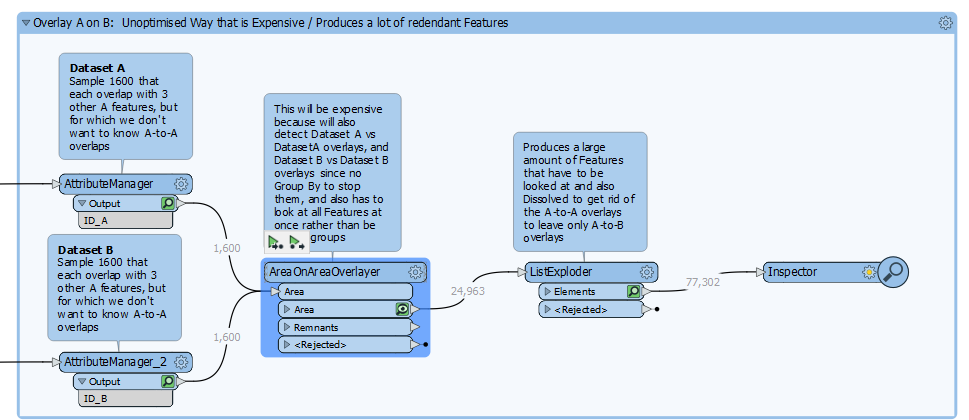
I can’t use the AreaonAreaOverlay as is since it explicitly states in the documentation that it doesn’t expect the input features to self intersect, and this is not true for A.
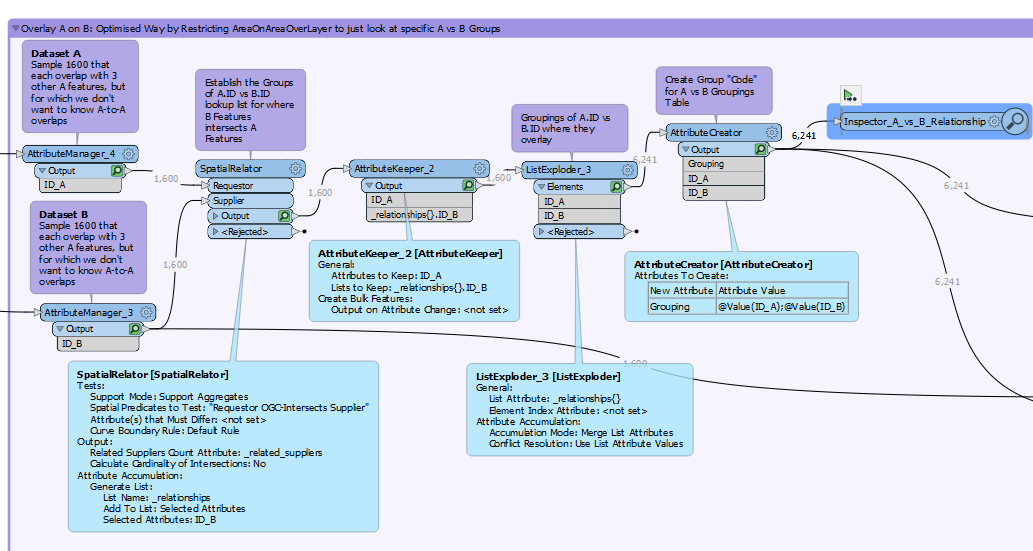
When I filter for a single polygon, The AreaonAreaOverlay generally gets me there, but, the problem is I want the output of all polygons.
Spatial relate doesn’t give me the intersection of the features, so I can’t calculate the % area overlap.
My preference would be to use geopandas.overlay and iterate over each polygon from A, but, my input data is stored in arc.SDE so converting them to gdf objects is more hassle than it seems worth to then convert back out into an FME feature object to then write to an SDE again.
I tried using arcpy.analysis.Intersect, but, the documentations indicates I should write to a gdb and I want to first concatenate the output since I still want to capture the output for each polygon. Additionally, this function doesn’t accept the input fme feature object in the first argument position.
Any help would be really appreciated!