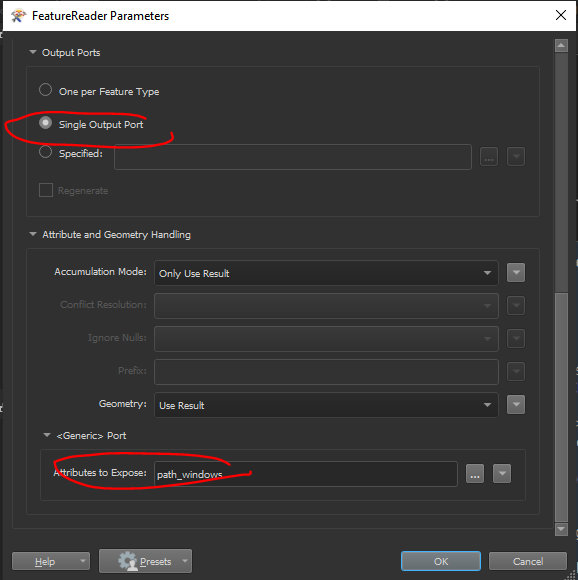
import os
def get_excel_file_paths(folder_path):
excel_file_paths = []
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith(".xlsx"):
excel_file_paths.append(os.path.join(root, file))
return excel_file_paths
folder_path = "/path/to/my/folder" ----I have a list of folders in a csv file which i read into the workspace so i plan to use that attribute here
excel_paths = get_excel_file_paths(folder_path)
for path in excel_paths:
print(path)
Having troubles converting this to run in fme
Thanks!




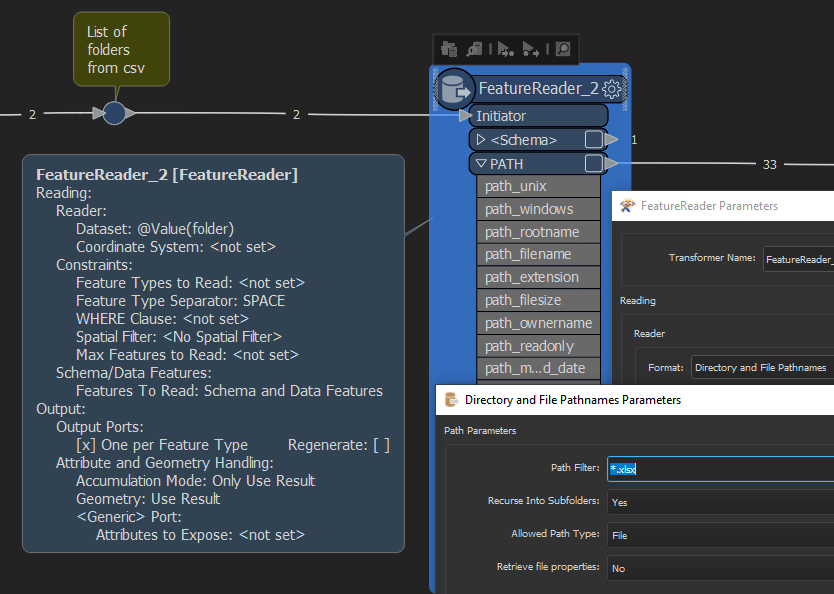




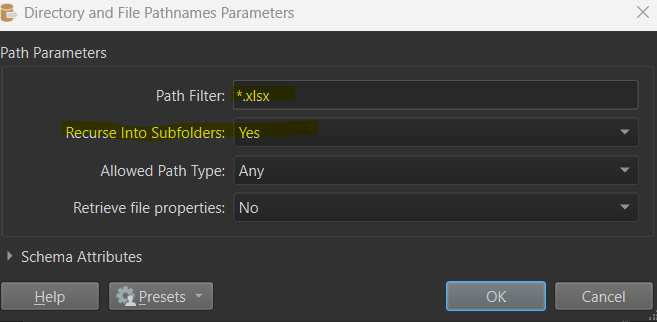 When setup you will get attributes for all the file paths and other ancillary information as attributes. This would satisfy looking into 1 folder location with subfolders (if present).
When setup you will get attributes for all the file paths and other ancillary information as attributes. This would satisfy looking into 1 folder location with subfolders (if present).